Pourquoi et quand exécuter cette tâche
Pour ce faire, procédez comme suit :
-
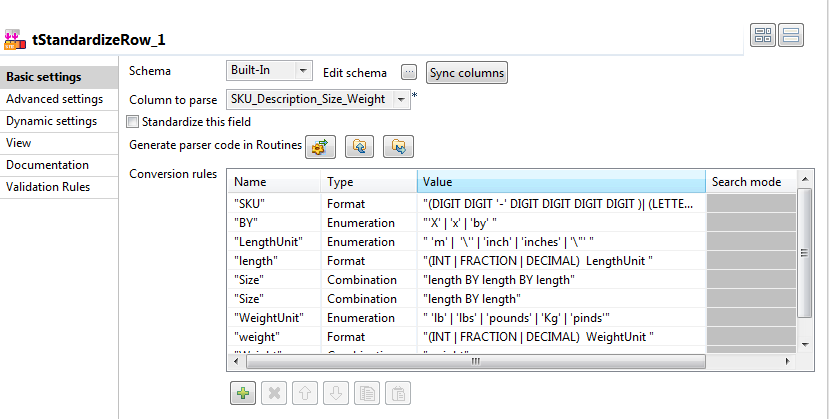
Cliquez sur le tStandardizeRow pour ouvrir sa vue Component.
-
Dans le champ Column to parse, sélectionnez SKU_Description_Size_Weight. C'est l'unique colonne que contient le schéma d'entrée.
-
Sous le tableau Conversion rules, cliquez sur le bouton [+] à huit reprises pour ajouter huit lignes à ce tableau.
-
Pour remplir ces lignes, saisissez les règles déterminées lors de l'analyse des données brutes effectuée au début de ce scénario.
Les deux règles Size sont exécutées par ordre décroissant. Dans ce scénario, l'ordre des règles permet au composant de mettre d'abord en correspondance la règle Size composée de trois nombres puis celles de deux nombres. Si vous inversez cet ordre, le composant met en correspondance les deux premiers nombres avec la première règle Size (Length BY Length) et traite ensuite le dernier nombre de la chaîne est ignoré car il ne correspondant pas.
-
Cliquez sur le bouton Generate parser code in routines.
-
Dans la vue Advanced settings, laissez les options par défaut dans la zone Output format.
Le paramètre Max edits for fuzzy match est configuré à 1 par défaut.