
Différents types de règles pour différents niveaux de parsing
Le composant tStandardizeRow utilise des règles simples basées sur la grammaire ANTLR et des règles avancées définies par Talend, non basées sur ANTLR.
3M PROJECT LAMP 7 LUMENS 32ML
A 5 LUMINES 5 LOW VANILLA 5L 5LIGHT 5 L DULUX L
54MLP FAC 32 MLVous devez d'abord définir une unité pour les liquides et une quantité de liquides dans des règles d'analyse simples, comme suit : 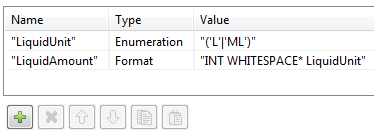
Si vous testez ces règles dans la perspective Profiling du Studio Talend, vous pouvez constater que ces règles extraient 7 L de 7 LUMENS et que ce n'est pas ce que vous attendiez. Vous ne souhaitez pas que le mot LUMENS soit divisé en deux jetons. 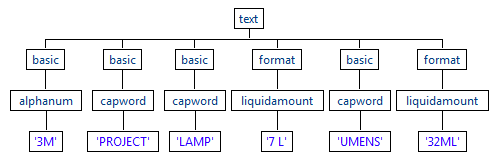
Les règles simples définies précédemment sont des règles ANTLR d'analyse lexicale et sont utilisées pour diviser en jetons la chaîne de caractères d'entrée. ANTLR ne fournit pas de symbole de limite, comme le \b dans les expressions régulières. Vous devez donc être prudent lors du choix de vos règles d'analyse lexicale, car elles définissent comment sont divisées en jetons les chaînes d'entrée.
Vous pouvez résoudre ce problème en utilisant deux approches différentes :
La première approche est la définition d'une autre règle simple mettant en correspondance un mot et une valeur numérique, la règle Amount dans cet exemple : 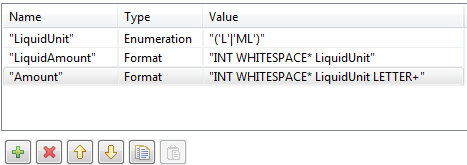
La règle simple est une règle d'analyse syntaxique, une règle Format commençant par une majuscule. Si vous testez cette règle dans la perspective Profiling du Studio Talend, vous pouvez constater que les quantités non liquides sont mises en correspondance par cette règle. La règle LiquidAmount met en correspondance uniquement les séquences attendues de caractères. 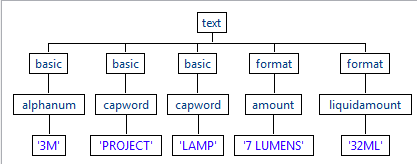
La seconde approche consiste en une règle avancée telle une expression régulière et en la définition d'une limite de mot avec \b. Vous pouvez utiliser un analyseur lexical afin de diviser en jetons les quantités pour lesquelles vous mettez en correspondance tout mot avec une valeur numérique. Ensuite, utilisez une expression régulière qui met en correspondance les quantités de liquide comme suit : un nombre suite d'un espace facultatif et suivi de L ou ML et terminé par une limite de mot. 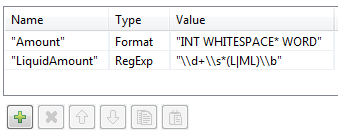
Notez que l'expression régulière va être appliquée sur les jetons créés par la règle d'analyse lexicale.
3M PROJECT LAMP 7 LUMENS 32ML
<record>
<Amount>3M</Amount>
<Amount>7 LUMENS</Amount>
<LiquidAmount>32ML</LiquidAmount>
<UNMATCHED>
<CAPWORD>PROJECT</CAPWORD>
<CAPWORD>LAMP</CAPWORD>
</UNMATCHED>
</record>Pour un exemple de Job concernant l'utilisation des règles ci-dessus, consultez Utilisation de deux niveaux de parsing pour extraire des informations de données non structurées.
La première approche utilise uniquement la grammaire ANTLR et peut être plus efficace que la seconde, qui nécessite une seconde passe de parsing, afin de vérifier chaque jeton par rapport à l'expression régulière. Les expressions régulières permettent aux personnes ayant une certaine connaissance de ces expressions de créer des règles plus avancées, qui ne pourraient pas vraiment être créées à l'aide d'ANTLR uniquement.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !