
Créer une connexion à une base de données Hive
Procédure
-
Cliquez sur Next pour passer à l'étape suivante et renseigner les informations de connexion à la base de données Hive. Parmi ces informations, les champs DB Type, Hadoop cluster, Distribution, Version, Server, NameNode URL et JobTracker URL sont automatiquement renseignés avec les propriétés héritées de la connexion Hadoop que vous avez sélectionnée dans les étapes précédentes.
Notez que si vous choisissez None dans la liste Hadoop cluster, vous basculez dans un mode manuel dans lequel les données héritées sont abandonnées. Vous devez donc configurer chaque propriété vous-même. La connexion créée apparaît sous le nœud Db connection uniquement.
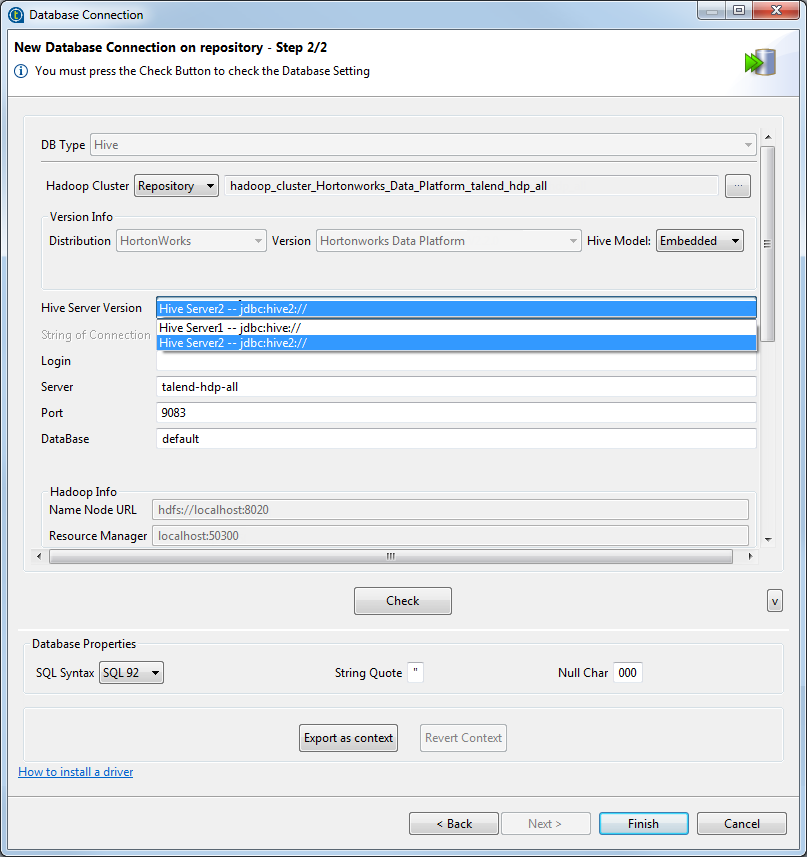 Les propriétés à définir peuvent varier suivant la distribution Hadoop utilisée.
Les propriétés à définir peuvent varier suivant la distribution Hadoop utilisée. -
Les champs affichés varient selon le modèle sélectionné.
Lorsque vous laissez le champ Database vide, sélectionnez le modèle Standalone pour autoriser la connexion à la base de données Hive default uniquement.
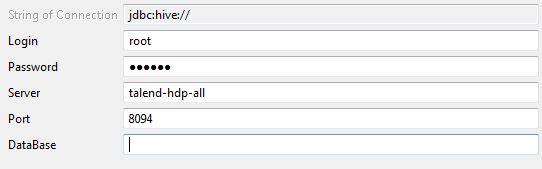
-
Si vous accédez à une distribution de Hadoop fonctionnant avec la sécurité Kerberos, cochez la case Use Kerberos authentication. Puis saisissez le nom du Principal Kerberos dans le champ Hive principal.
Si vous devez utiliser un fichier Keytab pour vous connecter, cochez la case Use a keytab to authenticate, saisissez le Principal à utiliser, dans le champ Principal, puis, dans le champ Keytab, parcourez votre système jusqu'au fichier Keytab à utiliser.
Un fichier Keytab contient les paires des Principaux et clés cryptées Kerberos. l'utilisateur ou l'utilisatrice exécutant un Job utilisant un fichier Keytab n'est pas nécessairement celui désigné par un Principal mais doit avoir le droit de lire le fichier Keytab utilisé. Par exemple, le nom d'utilisateur ou d'utilisatrice que vous utilisez pour exécuter le Job est user1 et le principal à utiliser est guest. Dans cette situation, assurez-vous que user1 a les droits de lecture pour le fichier keytab à utiliser.
Assurez-vous que Kerberos a bien été configuré dans le Studio Talend en suivant la procédure présentée dans cet article Comment utiliser Kerberos dans Talend Studio avec Big Data (en anglais).
Exemple

-
Si vous devez utiliser une configuration personnalisée pour la distribution d'Hadoop ou de Hive à utiliser, cliquez sur le bouton [...] à côté du champ Hadoop properties ou Hive Properties, pour ouvrir la table des propriétés correspondante et ajouter une ou des propriété(s) à personnaliser. Lors de l'exécution, les propriétés personnalisées écrasent celles par défaut utilisées par le Studio pour son moteur Hadoop.
Pour plus d'informations concernant les propriétés Hadoop, consultez la documentation Apache Hadoop (uniquement en anglais) (en anglais), ou la documentation de la distribution Hadoop que vous utilisez. Par exemple, cette page (uniquement en anglais) (en anglais) liste certaines propriétés Hadoop par défaut.Pour plus d'informations concernant les propriétés de Hive, consultez la documentation de Apache Hive. Par exemple, cette page (uniquement en anglais) (en anglais) décrit certaines propriétés de la configuration de Hive.Pour savoir comment tirer parti de ces tables des propriétés, consultez Configuration des propriétés réutilisables de Hadoop.
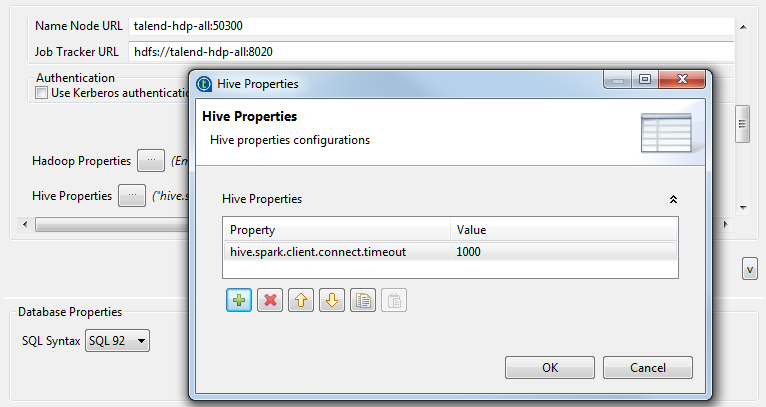
-
Cliquez sur Finish pour valider vos modifications et fermer l'assistant.
La nouvelle connexion spécifiée à la base de données Hive s'affiche sous le nœud DB Connections de la vue Repository. Cette connexion contient quatre sous-dossiers parmi lesquels Table schema peut regrouper tous les schémas relatifs à cette connexion.
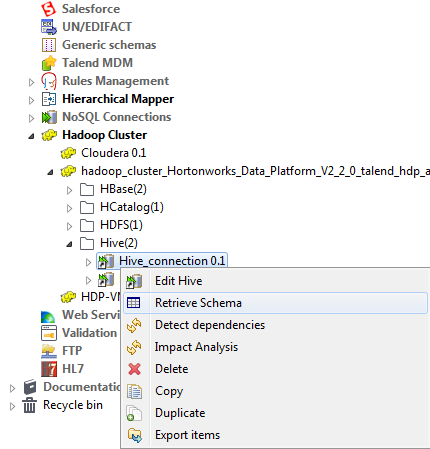 Si vous devez utiliser un contexte environnemental pour définir les paramètres de cette connexion, cliquez sur le bouton Export as context pour ouvrir l'assistant correspondant et choisir parmi les options suivantes :
Si vous devez utiliser un contexte environnemental pour définir les paramètres de cette connexion, cliquez sur le bouton Export as context pour ouvrir l'assistant correspondant et choisir parmi les options suivantes :-
Create a new repository context : créer le contexte environnemental depuis la connexion Hadoop actuelle, c'est-à-dire que les paramètres à configurer dans l'assistant sont pris comme variables de contexte avec les valeurs données à ces paramètres.
-
Reuse an existing repository context : utiliser les variables d'un contexte environnemental afin de configurer la connexion actuelle.
Pour un exemple pas-à-pas de l'utilisation de cette fonctionnalité Export as context, consultez Exporter une métadonnée en tant que contexte et réutiliser ses paramètres de contexte pour configurer une connexion.
-
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !