|
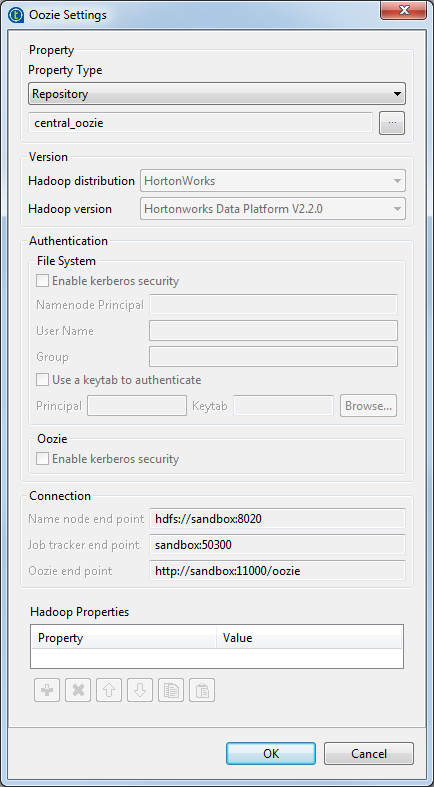
Hadoop distribution
|
Distribution Hadoop à laquelle vous connecter. Cette distribution héberge le système de fichiers HDFS à utiliser. Si vous sélectionnez Custom pour vous connecter à une distribution Hadoop personnalisée, cliquez sur le bouton [...] pour ouvrir la boîte de dialogue [Import custom definition]. Dans cette boîte de dialogue, importez les fichiers Jar requis par la distribution personnalisée.
Pour plus d'informations, consultez Connexion à une distribution Hadoop personnalisée.
|
|
Hadoop version
|
Version de la distribution Hadoop à laquelle vous connecter. Cette liste disparaît si vous sélectionnez Custom dans la liste Hadoop distribution.
|
| Enable kerberos security |
Si vous accédez au cluster Hadoop fonctionnant avec la sécurité Kerberos, cochez cette case, puis saisissez le Principal Name de Kerberos pour le NameNode dans le champ affiché. Cela vous permet d'utiliser votre identifiant pour vous authentifier, en le comparant aux identifiants stockés dans Kerberos.
Cette case est disponible ou non selon la distribution Hadoop à laquelle vous vous connectez.
|
| User Name |
nom d'utilisateur ou d'utilisatrice.
|
| Name node end point |
URI du NameNode, le cœur du système de fichier HDFS.
|
| Job tracker end point |
URI du nœud Job Tracker, qui sous-traite les tâches MapReduce dans des nœuds spécifiques du cluster.
|
| Oozie end point |
URI de la console Web d'Oozie, pour le monitoring de l'exécution du Job.
|
| Hadoop Properties |
Si vous devez utiliser une configuration personnalisée pour la distribution d'Hadoop à utiliser, renseignez cette table avec la ou les propriété(s) à personnaliser. Lors de l'exécution, les propriétés personnalisées écrasent celles par défaut utilisées par le Studio pour son moteur Hadoop.
Pour plus d'informations concernant les propriétés requises par Hadoop, consultez la documentation Apache Hadoop (uniquement en anglais) (en anglais).
Note InformationsRemarque :
Les paramètres configurés dans cette table sont effectifs dans le Job pour lequel ils ont été définis.
|