
Indicateurs de fréquence des modèles d'Asie de l'Est
| Indicator | Objectif |
|---|---|
| East Asia Pattern Frequency | Calcule le nombre d'enregistrements les plus fréquents pour chaque modèle distinct. |
| East Asia Pattern Low Frequency | Calcule le nombre d'enregistrements les moins fréquents pour chaque modèle distinct. |
Les deux indicateurs ci-dessus fonctionnent uniquement avec des caractères latins et sont disponibles uniquement avec le moteur Java. Ils sont utiles lorsque vous souhaiter identifier des modèles au sein de données asiatiques.
Les deux indicateurs ci-dessus présentent des modèles en convertissant des caractères asiatiques en lettre comme H,K,C et G en suivant les règles décrites dans le tableau suivant :
| Type de caractères | Utilisation |
|---|---|
| Chiffres latins | 9 remplace tous les chiffres ASCII. |
| Lettres minuscules latines | a remplace tous les caractères latins ASCII. |
| Latin uppercase letters | A remplace tous les caractères latins en majuscule. |
| Full-width Latin numbers | 9 remplace tous les chiffres ASCII. |
| Full-width Latin lowercase letters | a remplace tous les caractères latins ASCII. |
| Full-width Latin uppercase letters | A remplace tous les caractères latins en majuscule. |
| Hiragana | H remplace tous les caractères Hiragana |
| Katakana moyenne chasse | k remplace tous les caractères Katakana moyenne chasse |
| Full-width Katakana | K remplace tous les caractères Katakana pleine chasse |
| Katakana | K remplace tous les caractères Katakana |
| Kanji | C remplace les caractères chinois |
| Hangul | G remplace des caractères Hangeul. |
Consultez la documentation pour plus d'informations concernant les types de caractères asiatiques supportés dans les analyses de colonnes et sur les intervalles Unicode correspondants.
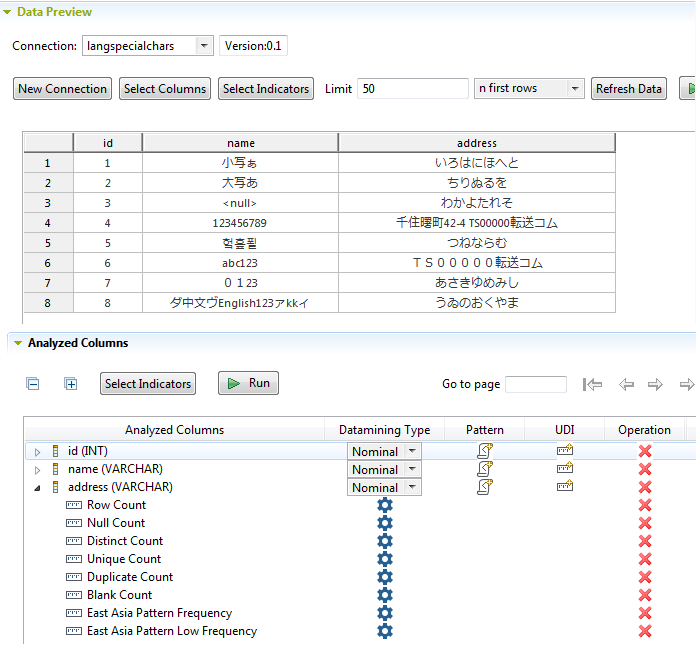
Voici un exemple d'analyse de colonnes utilisant les indicateurs East Asia Pattern Frequency et East Asia Pattern Low Frequency sur une colonne address.
Les résultats d'analyse de l'indicateur East Asia Pattern Low Frequency ressemblent à ceci :
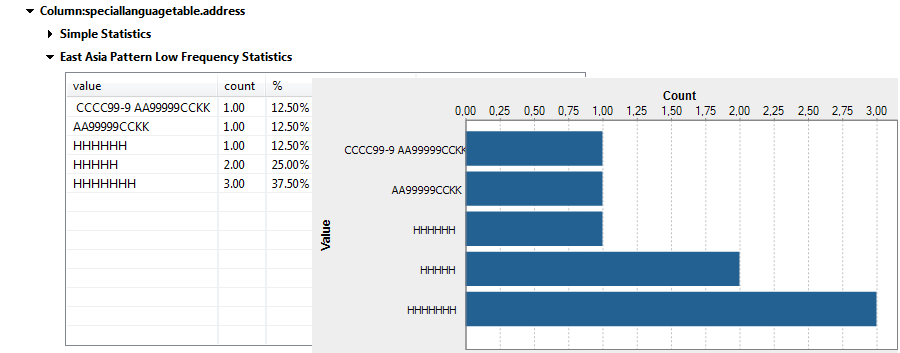
Ces résultats donnent le nombre d'enregistrements les moins fréquents pour chaque modèle distinct. Certains modèles ont des caractères et des nombres et d'autres contiennent uniquement des caractères. Les modèles ont également différentes longueurs, cela montre que les adresses ne sont pas cohérentes et que vous devez les corriger et les nettoyer.
Le tableau suivant présente les indicateurs que vous pouvez sélectionner dans n'importe quelle base de données :
| Type de données | Number | Text | Date | Autres | ||||
|---|---|---|---|---|---|---|---|---|
| Type de moteur d'analyse | Java | SQL | Java | SQL | Java | SQL | Java | SQL |
| East Asia Pattern Frequency |

|

|
|
|
|
|
|
|
| East Asia Pattern Low Frequency |
|
|
|
|
|
|
|
|
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !