
Planifier les exécutions d'un Job via Oozie (déprécié)
Procédure
-
Cliquez sur le bouton Schedule de l'onglet Oozie scheduler pour ouvrir la boîte de dialogue de planification.
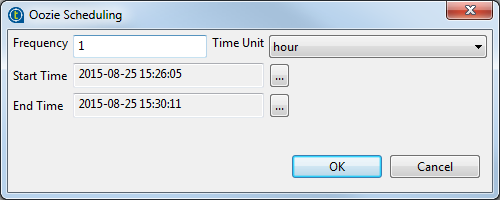
-
Cliquez sur le bouton [...] à côté du champ Start Time pour ouvrir la boîte de dialogue Select Date & Time et sélectionnez la date, l'heure, la minute et la seconde. Cliquez sur OK pour configurer l'heure de début de l'exécution du Job. De la même manière, configurez l'heure de fin d'exécution du Job.
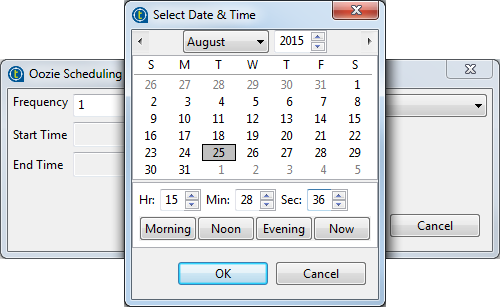
-
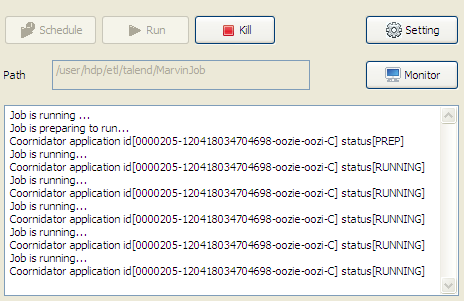
Cliquez sur OK pour fermer la boîte de dialogue et commencer les exécutions planifiées de votre Job.
Le Job s'exécute automatiquement selon les paramètres définis. Pour arrêter le Job, cliquez sur Kill.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !