
Types de caractères supportés dans les analyses de colonnes et les opérations de masquage
Lorsque vous masquez des données à l'aide de Talend Data Preparation ou du composant tDataMasking, chaque caractère dans les données d'entrée est transformé en un caractère appartenant au même type de caractères, dans l'un des intervalles Unicode supportés.
Lorsque vous créez une analyse de colonnes dans le Studio Talend, vous pouvez utiliser les indicateurs East Asia Pattern Frequency ou East Asia Pattern Low Frequency pour les caractères asiatiques, afin de définir le contenu, la structure et la qualité de données.
Le tableau ci-après décrit les types de caractères supportés et les intervalles Unicode correspondants (version 11.0).
Pour plus d'informations, consultez documentation for the Unicode Standard (uniquement en anglais) et character code charts (uniquement en anglais) (pages en anglais).
| Type de caractères | Intervalle Unicode (version 11.0) | Caractères correspondants |
|---|---|---|
| Chiffres latins (uniquement en anglais) | [0030-0039] | [0-9] |
| Latin lower-cased letters | [0061-007A] (uniquement en anglais) [00DF-00F6] [00F8-00FF] (uniquement en anglais) | [a-z] [ß-ö] [ø-ÿ] |
| Lettres majuscules latines | [0041-005A] (uniquement en anglais) [00C0-00D6] [00D8-00DE] (uniquement en anglais) | [A-Z] [À-Ö] [Ø-Þ] |
| Full-width Latin numbers (uniquement en anglais) | [FF10-FF19] | [0-9] |
| Lettres minuscules latines pleine chasse (uniquement en anglais) | [FF41-FF5A] | [A-Z] |
| Lettres majuscules latines pleine chasse (uniquement en anglais) | [FF21-FF3A] | [A-Z] |
| Hiragana (uniquement en anglais) | [3041-3096] 30FC 309D 309E | [ぁ-ゖ] ー ゝ ゞ |
| Katakana moyenne chasse (uniquement en anglais) | [FF66-FF9D] | [ヲ-ン] |
| Full-width Katakana (uniquement en anglais) | [30A1-30FA] 30FC 30FD 30FE | [ァ-ヺ] ー ヽ ヾ |
| Extensions phonétiques (uniquement en anglais) : [31F0-31FF] | [ㇰ-ㇿ] | |
| Kanji | Supplément A aux idéogrammes unifiés CJC (uniquement en anglais) : [4E00-9FEF] [3400-4DB5] | [一-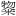 ] [㐀-䶵] ] [㐀-䶵] |
| Supplément B aux idéogrammes unifiés CJC (uniquement en anglais) : [20000-2A6D6] | [𠀀-𪛖] | |
| Supplément C aux idéogrammes unifiés CJC (uniquement en anglais) : [2A700-2B734] | [𪜀-𫜴] | |
| Supplément D aux idéogrammes unifiés CJC (uniquement en anglais) : [2B740-2B81D] | [𫝀-𫠝] | |
| Supplément E aux idéogrammes unifiés CJC (uniquement en anglais) : [2B820-2CEA1] | [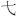 - - ] ] |
|
| Supplément F aux idéogrammes unifiés CJC (uniquement en anglais) : [2CEB0-2EBE0] | [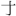 - - ] ] |
|
| Idéogrammes de compatibilité CJC (uniquement en anglais) : [F900-FA6D] [FA70-FAD9] | [豈-舘] [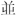 - -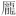 ] ] |
|
| Supplément aux idéogrammes de compatibilité CJC (uniquement en anglais) : [2F800-2FA1D] | [ - -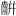 ] ] |
|
| Clés chinoises KangXi (uniquement en anglais) : [2F00-2FD5] | [⼀-⿕] | |
| Formes supplémentaires des clés CJC (uniquement en anglais) : [2E80-2E99] [2E9B-2EF3] | [⺀-⺙] [⺛-⻳] | |
| Symboles et ponctuation CJC (uniquement en anglais) : [3005-3005] [3007-3007] [3021-3029] [3038-303B] | [々-々] [〇-〇] [〡-〩] [〸-〻] | |
| Hangul (uniquement en anglais) | [AC00-D7AF] | [가-] |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !