
Configurer les composants
Procédure
-
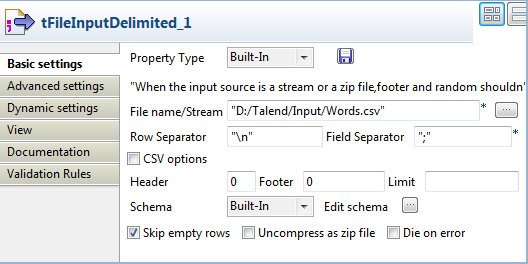
Double-cliquez sur le composant tFileInputDelimited pour ouvrir sa vue Basic settings.
-
Cliquez sur le bouton [...] à côté du champ Edit schema pour ouvrir la boîte de dialogue Schema, configurez le schéma d'entrée qui doit contenir une colonne nommée Word dans cet exemple.
 Cela fait, cliquez sur OK pour fermer la boîte de dialogue.
Cela fait, cliquez sur OK pour fermer la boîte de dialogue. -
Double-cliquez sur le composant tMap pour ouvrir l'éditeur de mapping. Le composant est utilisé pour diviser la colonne du flux d'entrée en un flux de données à deux colonnes permettant d'alimenter le composant tStem.

-
Double-cliquez sur le tStem pour ouvrir sa vue Basic settings.

-
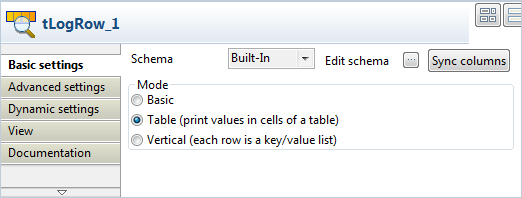
Double-cliquez sur le composant tLogRow pour ouvrir sa vue Basic settings. Sélectionnez l'option Table pour un meilleur affichage des résultats d'exécution du Job.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !