
Déploiement d'un Job ou d'une Route en mode cluster
Pour déployer votre Job en mode cluster, vous devez avoir groupé vos serveurs physiques en un serveur virtuel via la page Virtual Servers, comme expliqué dans Configuration des serveurs virtuels.
-
si l'un des serveurs physiques d'un serveur virtuel donné a le meilleur score (Rate), ce serveur physique peut être utilisé pour les exécutions des tâches.
-
si tous les serveurs physiques ont le même score, le premier serveur physique du serveur virtuel sera utilisé pour les exécutions des tâches.
Pour plus d'informations concernant le classement des serveurs (basé sur l'espace disque, l'utilisation des processeurs et de la RAM, etc.) qui détermine quel serveur physique utiliser pour les exécutions et concernant la modification de ces valeurs de pondération, consultez Configuration des serveurs d'exécution et Configurer les indicateurs qui déterminent quel serveur utiliser pour la répartition de charge.
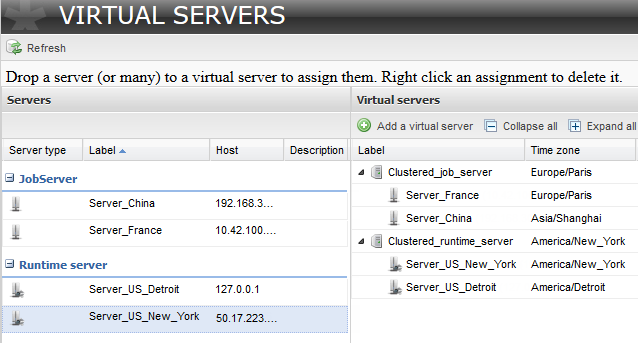
Ce serveur en cluster est utilisé pour distribuer les requêtes entrantes (génération, déploiement et exécution de Job) entre les serveurs physiques et pour assurer que ces requêtes sont bien traitées, même si l'un des serveurs physiques est indisponible.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !