
Configurer et exécuter votre Job Spark avec CDP Public Cloud Data Hub sur AWS
Le Studio Talend vous permet de déployer et d'exécuter vos Jobs Spark Batch et Spark Streaming sur un Talend JobServer distant avec une instance de CDP Public Cloud Data Hub sur AWS.
Avant de commencer
- Les paramètres du Talend JobServer doivent être configurés dans le Studio Talend pour exécuter votre Job à distance. Pour plus d'informations, consultez Configuration de l'exécution à distance (Talend > Run/Debug).
- L'environnement de l'instance AWS est défini dans Cloudera Management Console. Pour plus d'informations, consultez Register an AWS environment, dans la documentation officielle de Cloudera.
- Le cluster sur AWS est défini dans Cloudera Management Console. Pour plus d'informations, consultez Create a custom cluster on AWS, dans la documentation officielle de Cloudera.
Procédure
-
Connectez-vous à votre console Cloudera Management et allez dans l'onglet Data Hub Clusters, puis dans l'onglet Hardware.
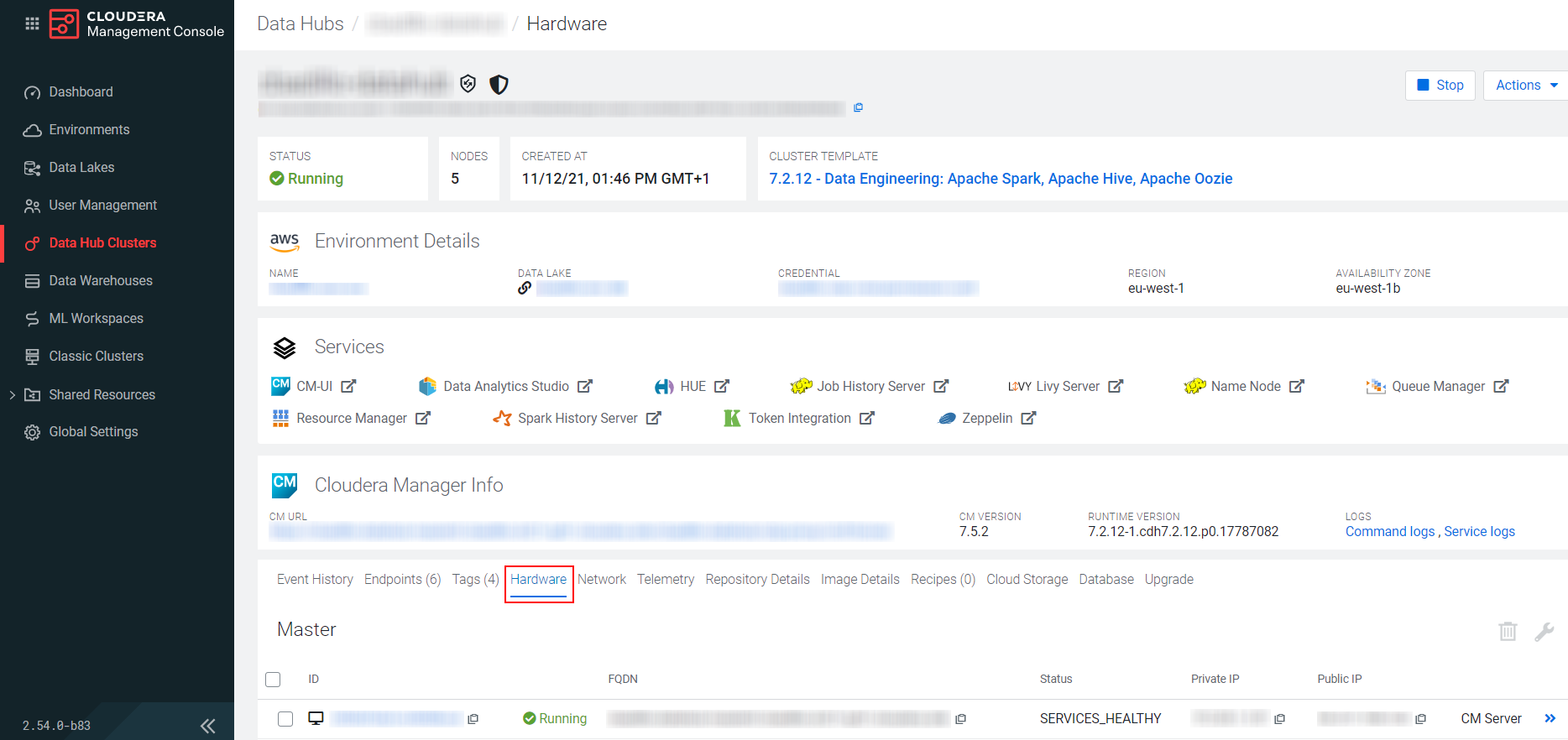
-
Connectez-vous à AWS Management Console et, dans VPC Management Console, assurez-vous que les ports dans les onglets Inbound rules et Outbound rules configurés pour le Talend JobServer sont ouverts.
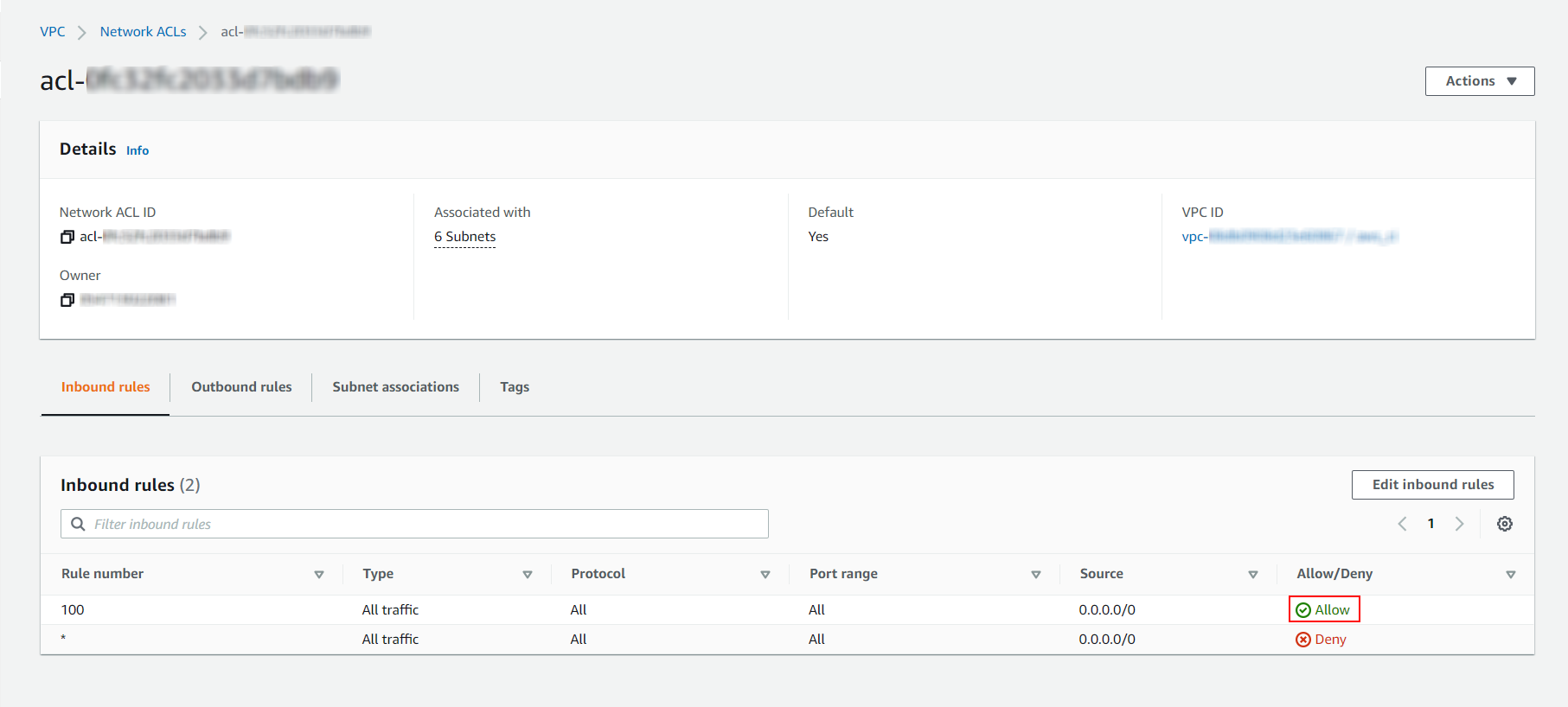
-
Connectez-vous à Cloudera Manager et, dans l'onglet Clusters, téléchargez tous les fichiers de configuration de votre cluster, puis dézippez-les au même emplacement de votre machine locale.
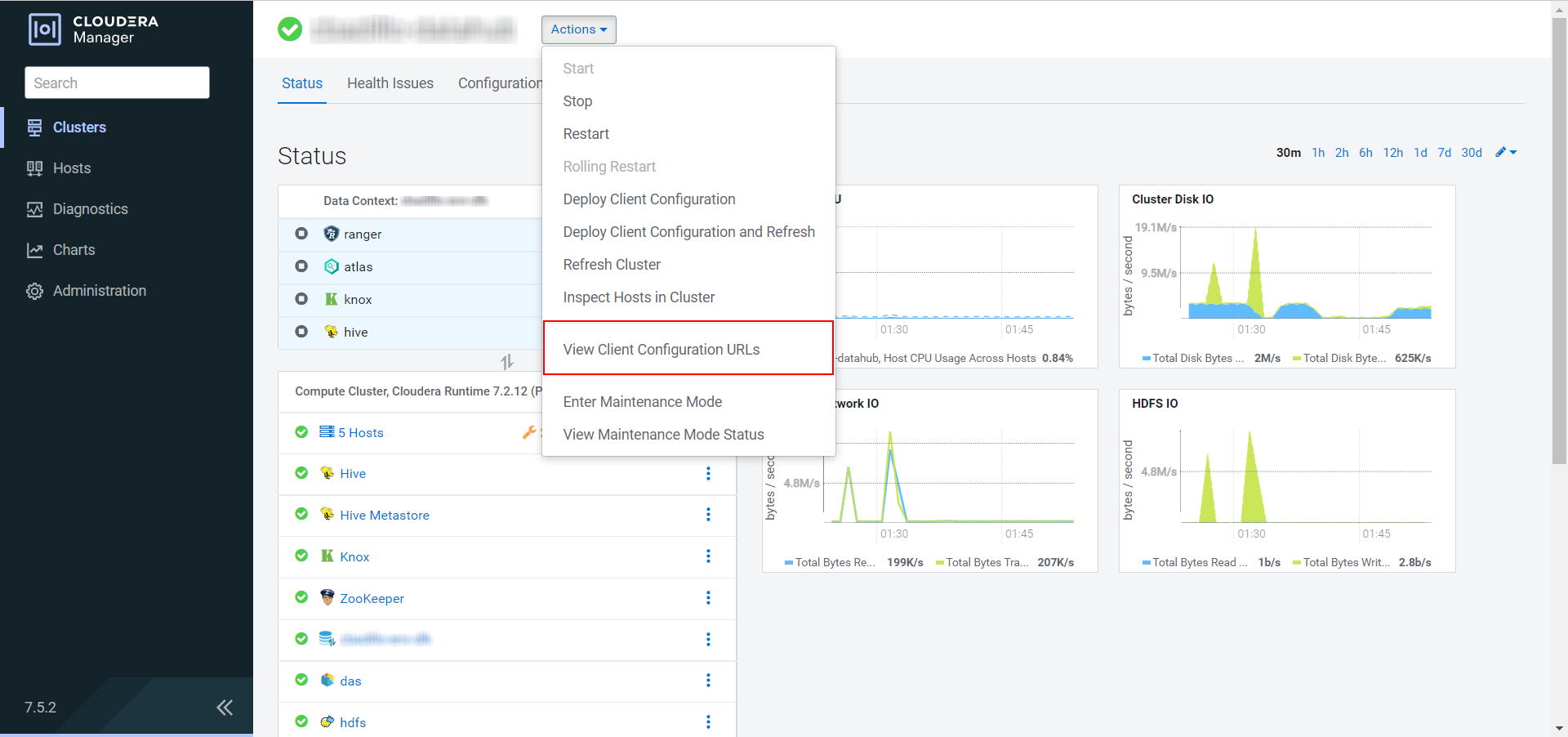
-
Connectez-vous au Studio Talend et configurez manuellement la connexion à Hadoop, à l'aide de l'option Import configuration from local files. Pour plus d'informations, consultez la troisième étape, dans Définition de la connexion à Hadoop.
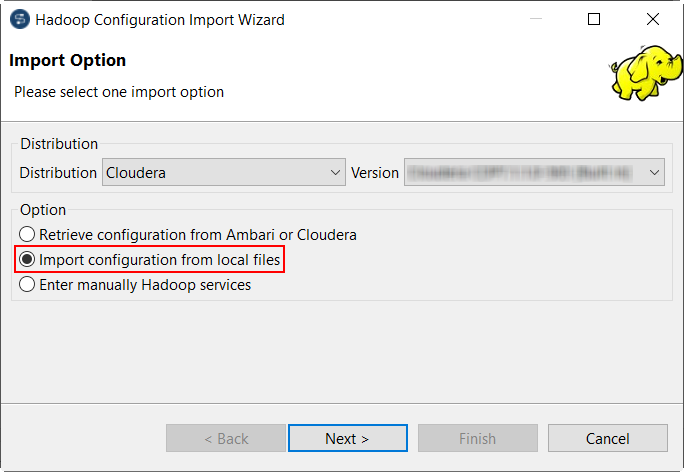 Note InformationsRemarque :
Note InformationsRemarque :- Vous n'avez pas besoin de sélectionner une version Cloudera dans la liste déroulante. Comme le Studio Talend utilise les fichiers de configuration provenant des clusters d'instances CDP Public Cloud, il va utiliser la version du moteur d'exécution définie dans ces fichiers.
- Vous devez donc activer le SSL et Kerberos.
Résultats
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !