
Configurer la première passe
Procédure
-
Cliquez sur le bouton Preview pour afficher l'assistant Configuration Wizard.
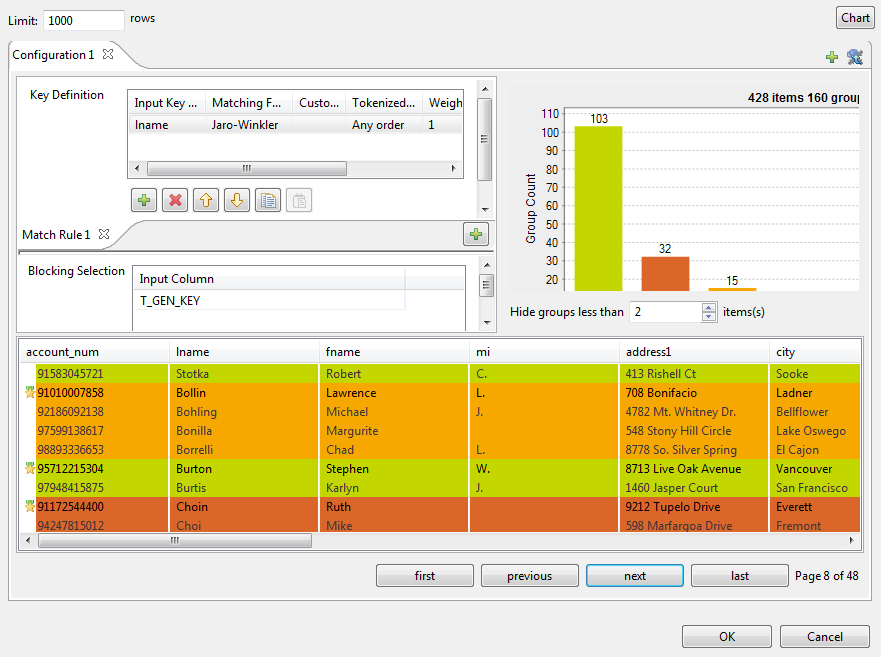
-
Cliquez sur
 et importez les clés de rapprochement depuis les règles de rapprochement créées et testées dans la perspective Profiling du Studio Talend et utilisez-les dans votre Job. Sinon, définissez les paramètres, des clés de rapprochement comme décrit dans les étapes ci-dessous.
Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes.
et importez les clés de rapprochement depuis les règles de rapprochement créées et testées dans la perspective Profiling du Studio Talend et utilisez-les dans votre Job. Sinon, définissez les paramètres, des clés de rapprochement comme décrit dans les étapes ci-dessous.
Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes. -
Si nécessaire, cliquez sur le bouton Edit schema pour ouvrir l'éditeur de schéma et visualiser le schéma récupéré du composant précédent dans le Job.

Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !