
Écrire et lire des données depuis S3 (Databricks sur AWS)
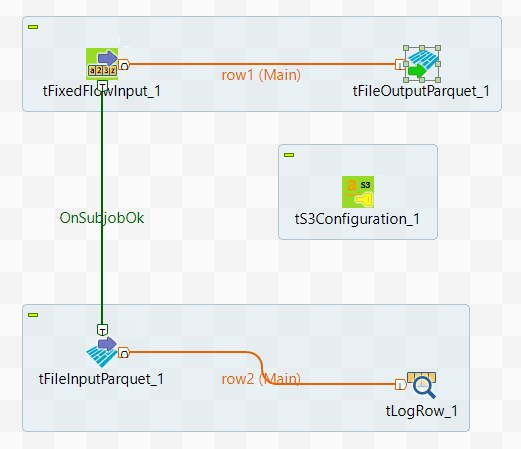
Dans ce scénario, vous allez créer un Job Spark Batch utilisant un tS3Configuration et les composants Parquet pour écrire des données dans S3 et les lire depuis S3.
Ce scénario s'applique uniquement aux produits Talend avec Big Data nécessitant souscription.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
L'échantillon de données utilisé est le suivant :
01;ychenCes données contiennent un identifiant utilisateur·rice et un ID distribué à cet·te utilisateur·rice.
Notez que les données d'exemple sont créées à des fins de démonstration uniquement.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !