
Écrire en sortie les données triées
Procédure
-
Double-cliquez sur le composant tRecollector pour ouvrir sa vue Component.
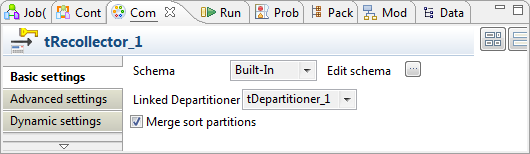
-
Cliquez sur le bouton
 à côté du champ Edit schema pour ouvrir l'éditeur de schéma, puis collez le schéma du tPartitioner précédemment copié lors de la configuration du tPartitioner.
Le schéma doit être cohérent par rapport à celui du tDepartitioner, fournissant les données au tRecollector.
à côté du champ Edit schema pour ouvrir l'éditeur de schéma, puis collez le schéma du tPartitioner précédemment copié lors de la configuration du tPartitioner.
Le schéma doit être cohérent par rapport à celui du tDepartitioner, fournissant les données au tRecollector. -
Double-cliquez sur le tFileOutputDelimited pour ouvrir sa vue Component.
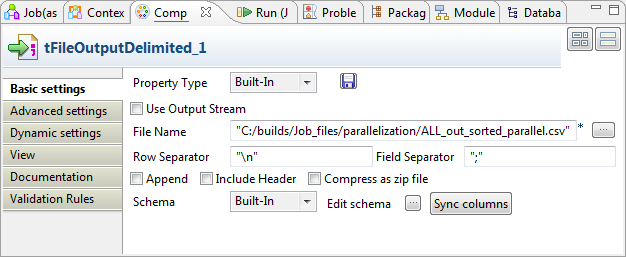
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !