
Accéder aux données sélectionnées
Procédure
-
Double-cliquez sur le tCacheOut pour ouvrir sa vue Component.
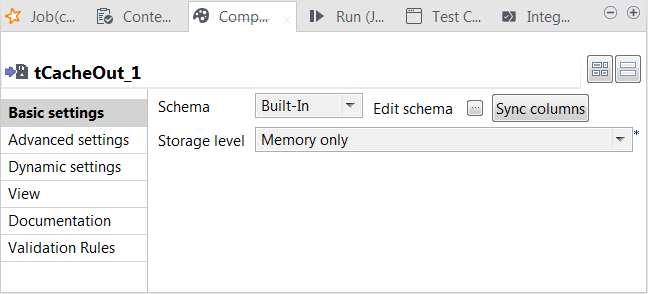 Ce composant stocke les données sélectionnées dans le cache.
Ce composant stocke les données sélectionnées dans le cache. -
Du côté de la sortie de l'éditeur du schéma, cliquez sur le bouton
 pour exporter le schéma dans le système de fichiers local et cliquez sur OK pour fermer l'éditeur.
pour exporter le schéma dans le système de fichiers local et cliquez sur OK pour fermer l'éditeur.
-
Double-cliquez sur le tCacheIn pour ouvrir sa vue Component.
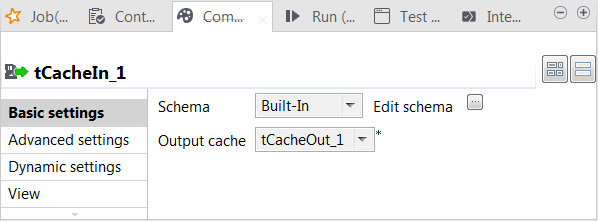
-
Cliquez sur le bouton [...] à côté du champ Edit schema pour ouvrir l'éditeur du schéma et cliquez sur le bouton
 pour importer le schéma exporté dans l'étape précédente. Cliquez sur OK afin de fermer l'éditeur.
pour importer le schéma exporté dans l'étape précédente. Cliquez sur OK afin de fermer l'éditeur.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !