
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support du format de table Iceberg dans le tHiveCreateTable dans les Jobs Standards | Vous pouvez à présent créer une table Iceberg avec le tHiveCreateTable dans des Jobs Standards, en utilisant une distribution Cloudera ou Amazon EMR. Utiliser des tables Iceberg vous permet de travailler avec différents formats de fichiers, comme Parquet, ORC et Avro, avec des distributions Cloudera et Parquet, uniquement avec des distributions Amazon EMR. 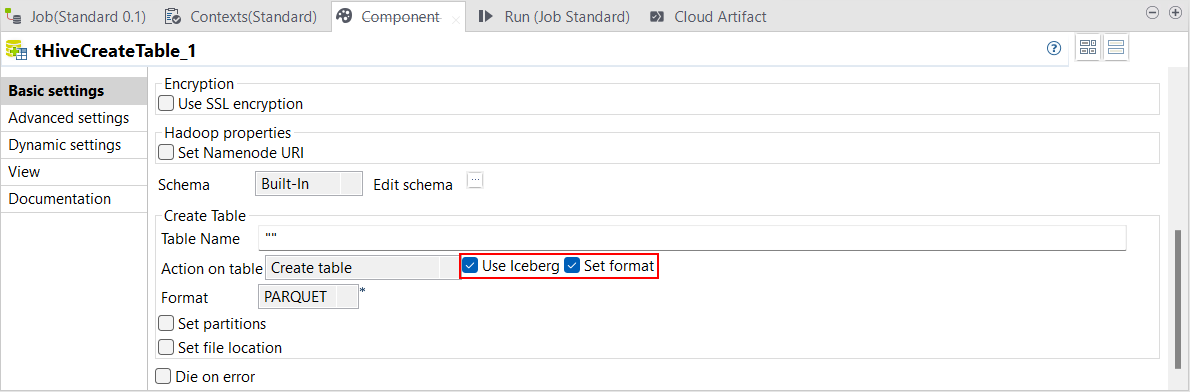
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Nouveau composant tHBaseNamespace permettant de créer des espaces de noms pour les tables HBase dans des Jobs Standards | Un nouveau composant, le tHBaseNamespace, est disponible dans vos Jobs Standards du Studio Talend. Ce composant vous permet de créer un espace de noms pour les tables HBase.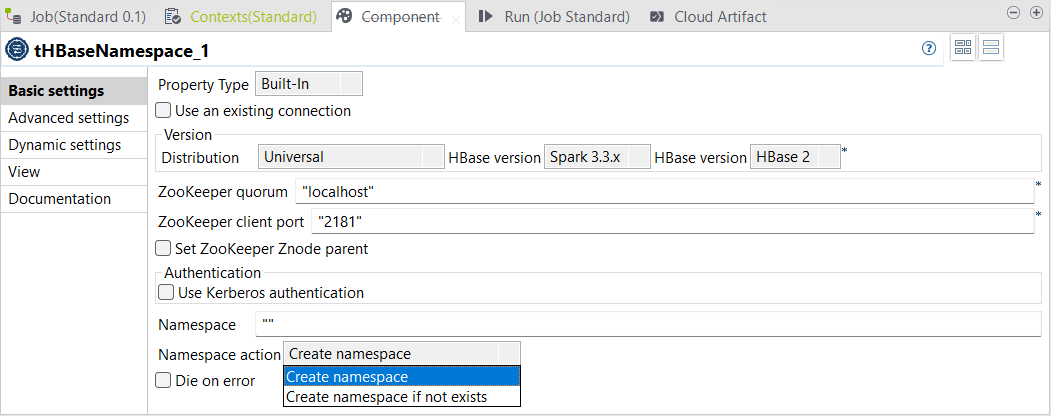
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de HDInsight 5.0 avec Spark Universal 3.1.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Spark Streaming sur HDInsight avec Spark Universal 3.1.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop), soit avec un stockage ADLS Gen2, soit avec un stockage Azure. Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 5.0 de HDInsight. Vous devez désactiver Log4j dans les composants pour pouvoir exécuter vos Jobs Spark sur HDInsight. Pour ce faire, allez dans et décochez la case Activate log4j in components (Activer Log4j dans les composants). 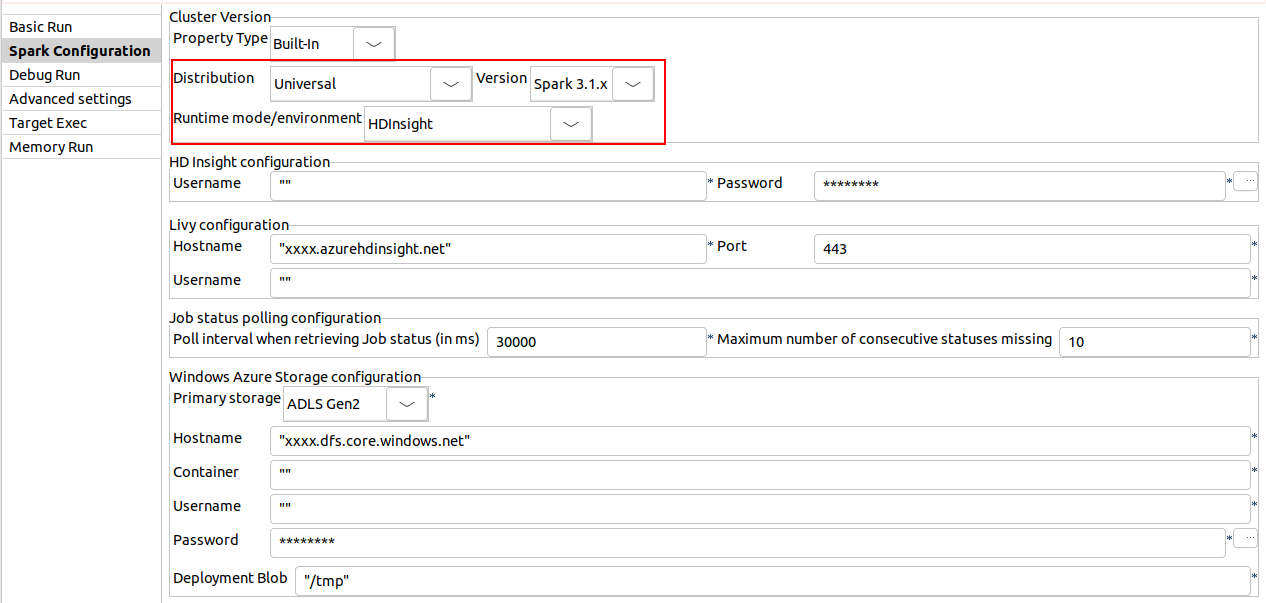
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support d'AWS EMR Serverless 6.6.0 avec Spark Universal 3.2.x et 3.3.x | Vous pouvez à présent exécuter vos Jobs Spark Batch sur AWS EMR Serverless avec Spark Universal 3.2.x et 3.3.x. Vous pouvez le configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark Batch. Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 6.6.0 d'AWS EMR Serverless. 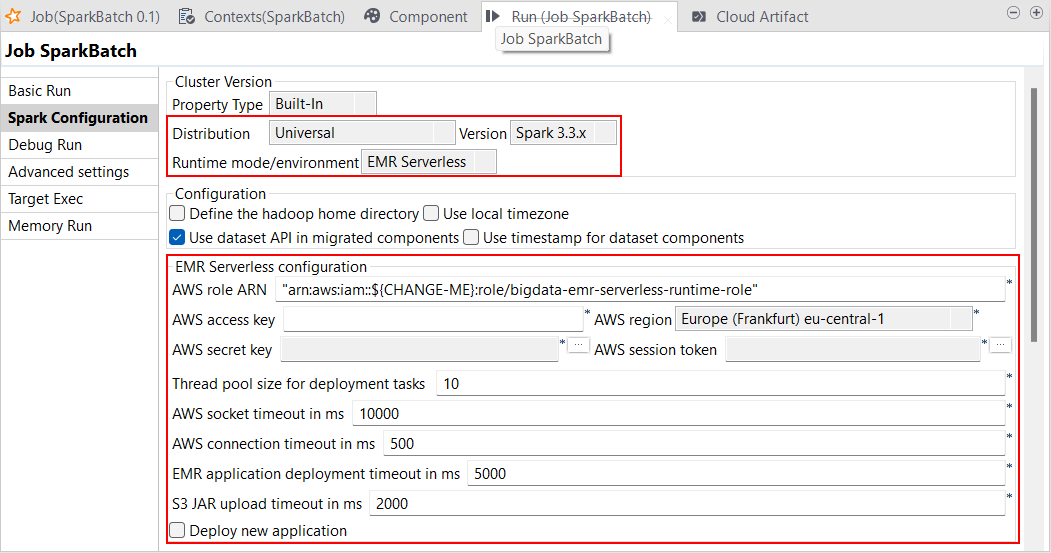
|
Tous les produits Talend avec Big Data nécessitant souscription |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !