
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support de Spark Universal 3.4.x en mode Local | Vous pouvez à présent exécuter vos Jobs Spark et Spark Streaming à l'aide de Spark Universal avec Spark 3.4.x en mode Local. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop).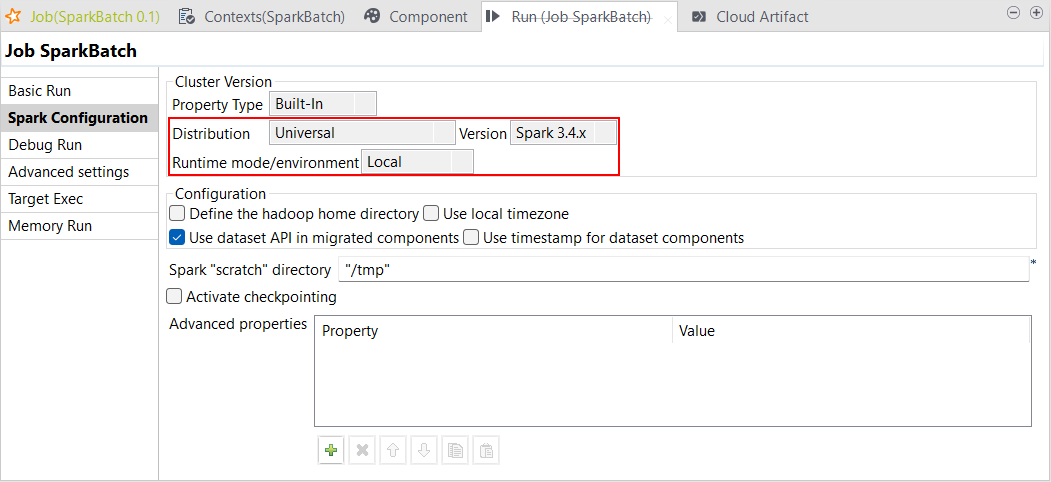
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support des paramètres personnalisés d'd'AWS EMR Serverless avec Spark Universal 3.2.x et 3.3.x dans des Jobs Spark Batch | Vous avez à présent la possibilité de personnaliser les paramètres de vos Jobs Spark Batch sur AWS EMR Serverless avec Spark Universal 3.2.x et 3.3.x. Cette configuration s'effectue dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark Batch, en cochant la case Custom settings (Paramètres personnalisés). Ce nouveau paramètre vous permet de contrôler tous les paramètres, y compris la capacité pré-analysée ou la connexion au réseau, par exemple. 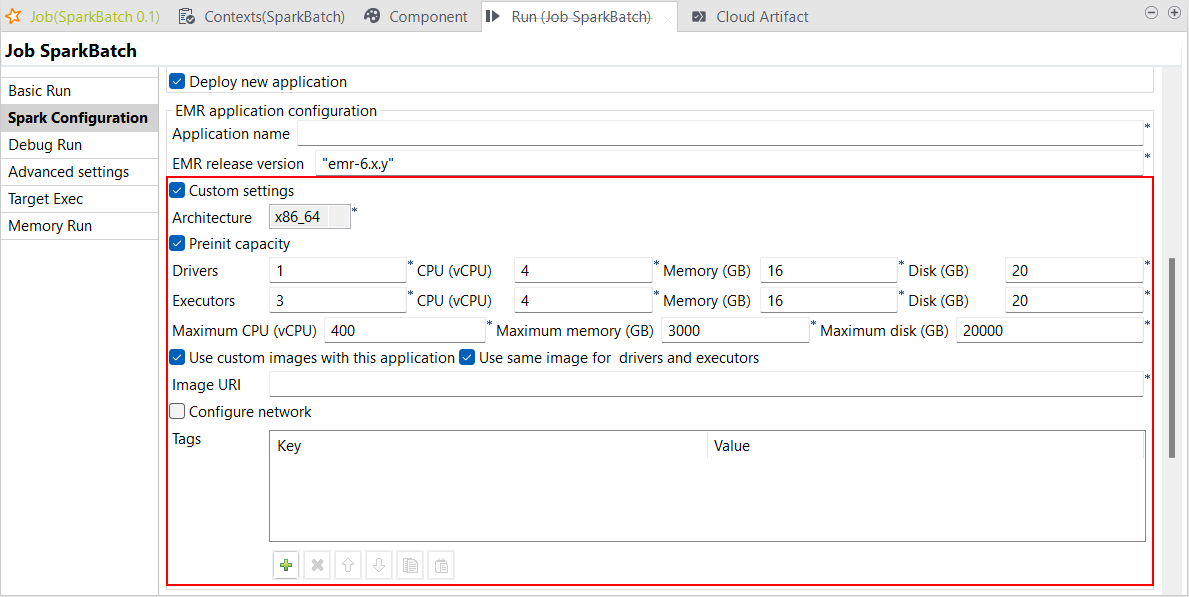
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de Dataproc 2.1 et supérieures avec Spark Universal 3.3.x dans des Jobs Spark Batch | Vous pouvez à présent exécuter vos Jobs Spark Batch sur Dataproc avec Spark Universal 3.3.x. Vous pouvez le configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark Batch. Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 2.1.x de Dataproc et ses versions supérieures. 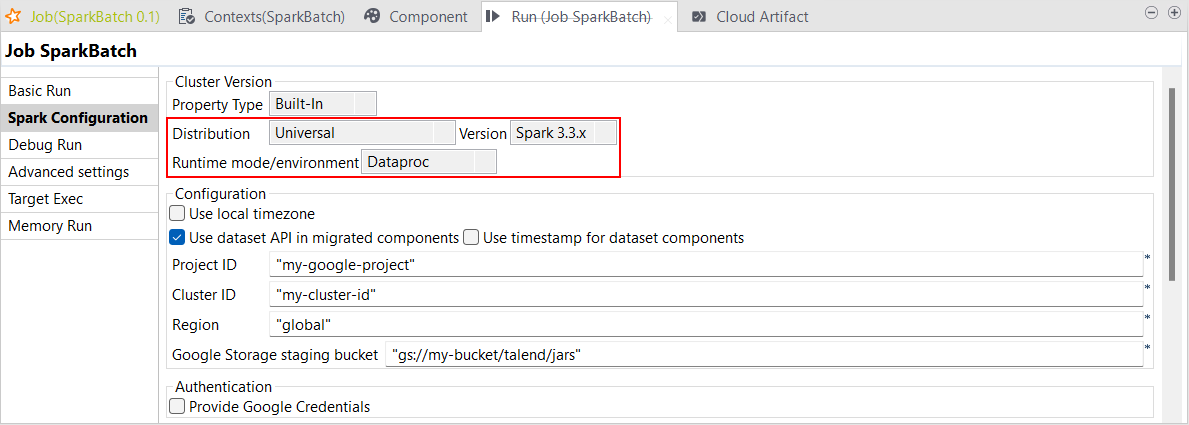
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support de Dataproc 2.1 et supérieures avec Spark Universal 3.3.x dans des Jobs Standards | Les Jobs Standards contenant des composants Hive supportent à présent Dataproc 2.1 et supérieures avec Spark Universal 3.3.x.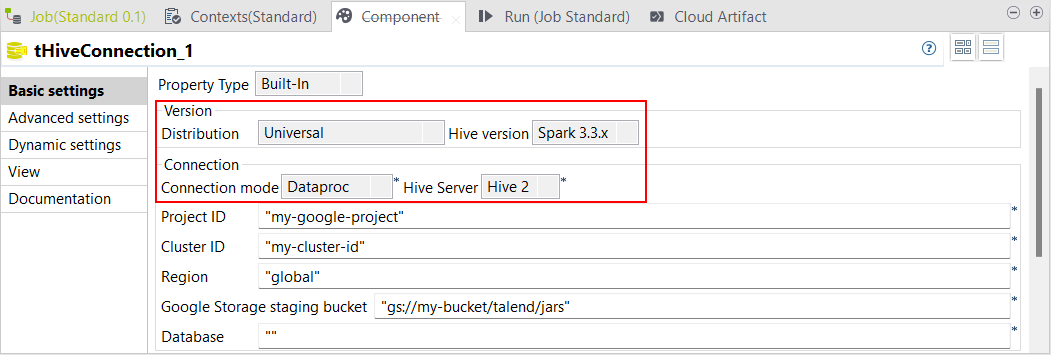
|
Tous les produits Talend avec Big Data nécessitant souscription |
| Support des scripts Spark-submit avec Universal 3.3.x dans les Jobs Spark Batch | Le mode Spark-submit des scripts vous permet de tirer parti d'un cluster HPE Ezmeral Data Fabric v9.1.x pour exécuter vos Jobs Spark Batch. Vous pouvez également utiliser ce mode avec d'autres clusters. Cela est possible car les scripts Spark-submit sont conçus pour fonctionner avec tous les gestionnaires de clusters supportés par Spark, comme vous pouvez le constater dans la documentation Spark cluster managers (en anglais). |
Tous les produits Talend avec Big Data nécessitant souscription |
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !