
Configurer le Job pour agréger et filtrer des données dans plusieurs tables SAP
Procédure
-
Cliquez sur le tELTSAPMap, puis sur l'onglet Component pour ouvrir sa vue Basic settings.
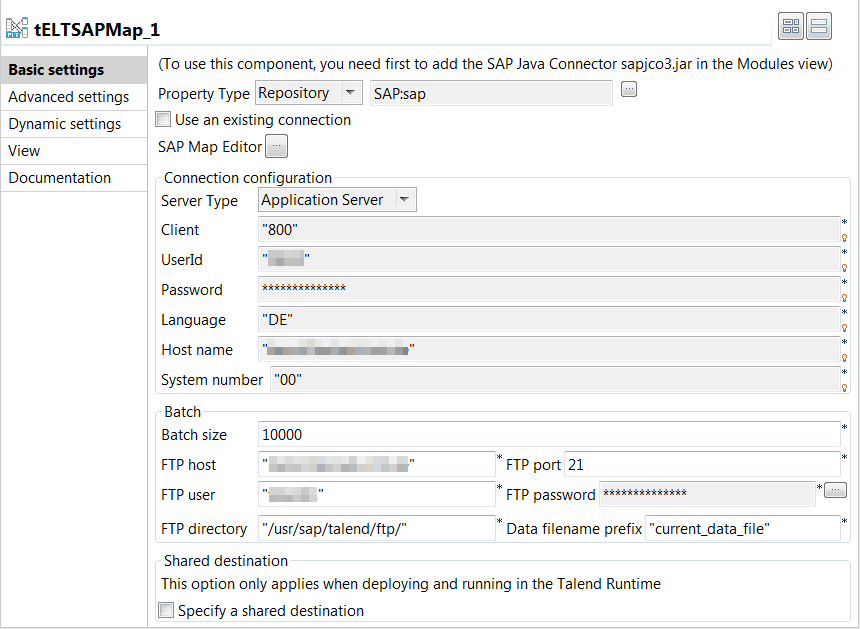
-
Cliquez sur le bouton [...] à côté du champ SAP Map Editor pour ouvrir son éditeur de mapping.
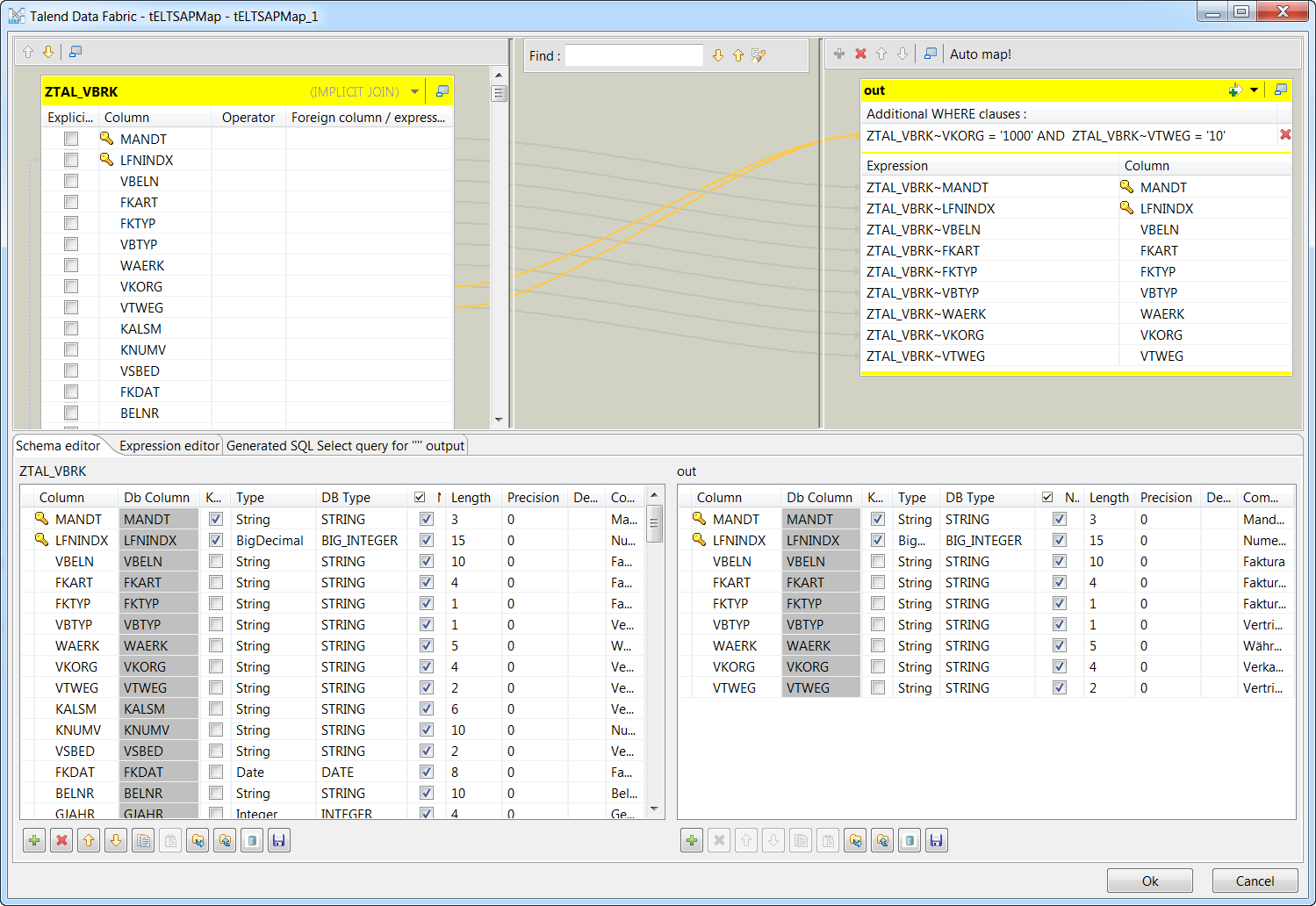
-
Cliquez sur l'onglet Generated SQL Select query for "" output, vous allez voir la requête SQL SELECT générée utilisée pour agréger et filtrer les données des deux tables.
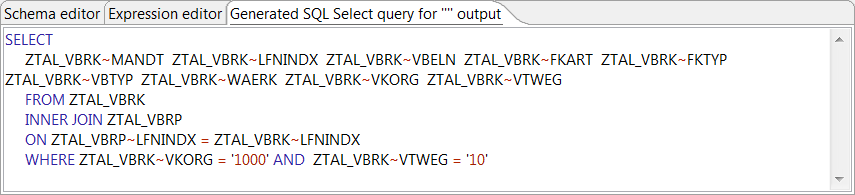
Cela fait, cliquez sur OK pour fermer l'éditeur de mapping.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !