
Explorer les catégories sémantiques des colonnes de données
Pourquoi et quand exécuter cette tâche
Procédure
-
Cliquez-droit sur la table et sélectionnez Semantic-aware Analysis ou cliquez-droit sur un ensemble de colonnes dans la table et sélectionnez Semantic-aware Analysis.
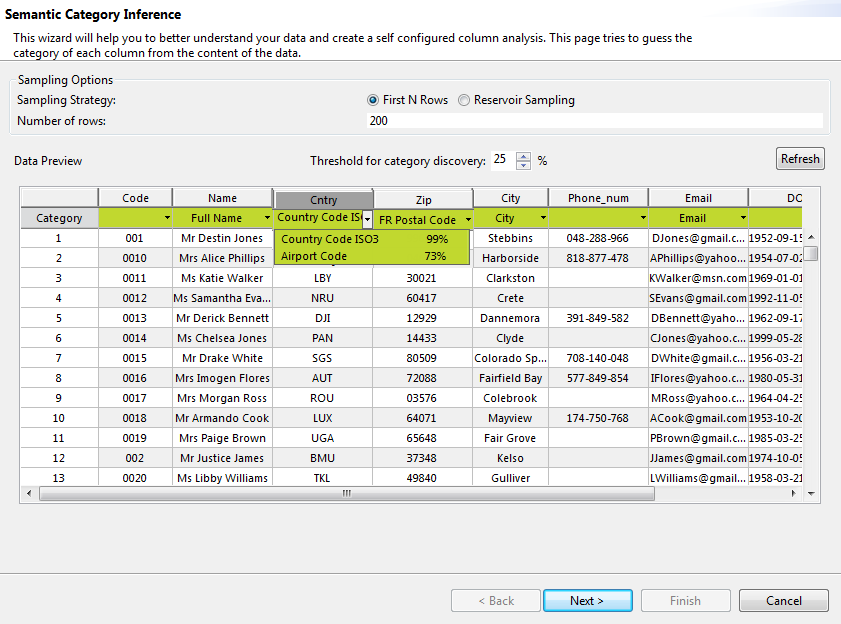
L'assistant sémantique s'ouvre, liste toutes les colonnes de la table ou liste les ensembles de colonnes sélectionnés, si votre analyse est une analyse de table ou d'un ensemble de colonnes, respectivement. La ligne Category dans l'assistant assigne des catégories sémantiques aux colonnes rapprochées.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !