
Configurer le lignage de données avec Atlas
Le support d'Apache Atlas a été ajouté aux Jobs Spark de Talend.
Si vous utilisez Hortonworks Data Platform V2.4 ou supérieure pour exécuter vos Jobs et qu'Apache Atlas a été installé dans votre cluster Hortonworks, vous pouvez utiliser Atlas afin de visualiser le lignage d'un flux de données pour découvrir comment ces données ont été générées par un Job Spark, notamment dans les composants utilisés dans ce Job et voir les modifications des schémas entre les composants. Si vous utilisez CDP Private Cloud Base ou le Cloud Public CDP pour exécuter vos Jobs et qu'Apache Atlas a été installé dans votre cluster, vous pouvez à présent utiliser Atlas.
Si vous utilisez une distribution CDP dynamique, la case Use Atlas (Utiliser Atlas) remplace la case Use Cloudera Navigator (Utiliser Cloudera Navigator) lorsque vous avez installé la version mensuelle 8.0.1-R2023-06 du Studio Talend ou une plus récente fournie par Talend.
- Hortonworks Data Platform V2.4, le Studio Talend supporte uniquement Atlas 0.5.
- Hortonworks Data Platform V2.5, le Studio Talend supporte uniquement Atlas 0.7.
- Hortonworks Data Platform V3.14, le Studio Talend supporte uniquement Atlas 1.1.
Par exemple, si vous avez créé le Job Spark Batch suivant et que vous souhaitez générer les informations de lignage le concernant dans Atlas :
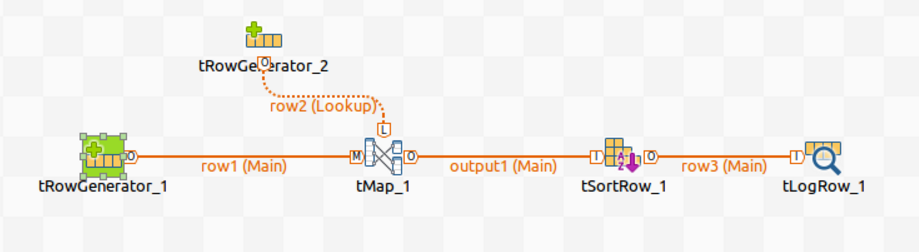
Dans ce Job, le tRowGenerator est utilisé pour générer les données d'entrée, le tMap et le tSortRow sont utilisés pour traiter les données et les autres composants pour écrire les données en sortie dans différents formats.
Procédure
Résultats
La connexion à Atlas a été configurée. Lorsque vous exécutez ce Job, le lignage est automatiquement généré dans Atlas.
Notez que vous devez configurer les autres paramètres dans l'onglet Spark configuration pour exécuter le Job avec succès. Pour plus d'informations, consultez Créer un Job Spark Batch.
Lorsque l'exécution du Job est terminée, effectuez une seconde recherche dans Atlas pour trouver les informations de lignage écrites par ce Job et pour y lire le lignage.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !