
Configurer le composant d'entrée
Avant de commencer
Vous avez téléchargé le fichier tJapaneseTokenize_standard_scenario.zip.
Procédure
-
Double-cliquez sur le tFileInputDelimited pour ouvrir sa vue Basic settings dans l'onglet Component.
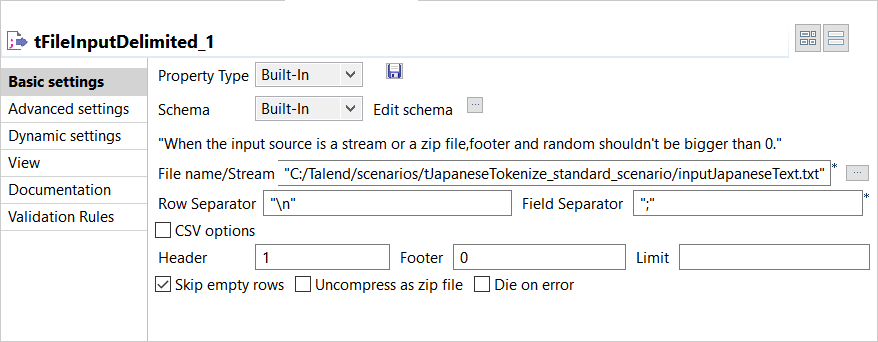
-
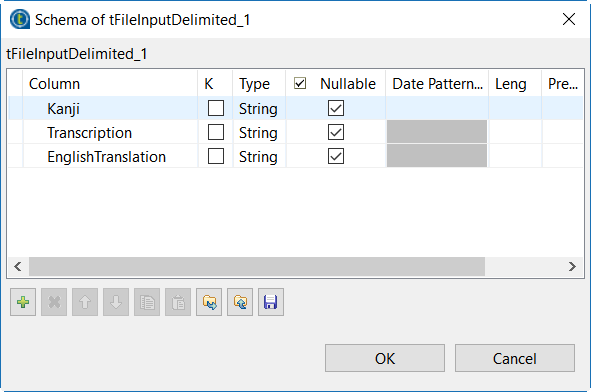
Cliquez sur le bouton [+] pour ajouter des colonnes au schéma.
Exemple
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !