
Modèles de lookups dans le tMap
Pour vous permettre de sélectionner le modèle le mieux adapté à vos besoins, cet article détaille tous les modèles.
Trois types de modèles de chargement de Lookup sont fournis, correspondants à différents besoins métier :- Charge une fois
- Recharger à chaque ligne
- Recharge à chaque ligne (cache)
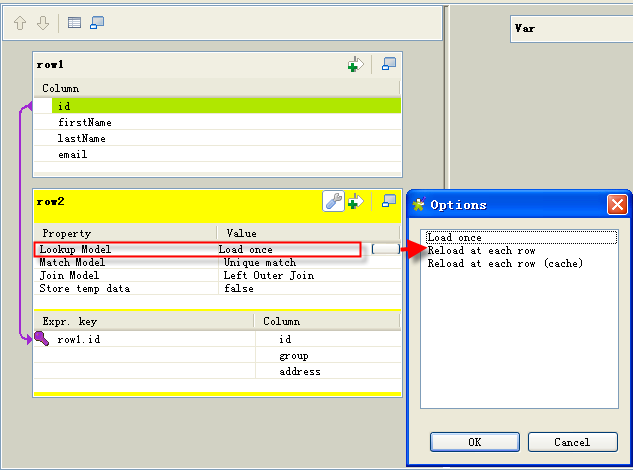
Lorsque vous implémentez une jointure (notamment Inner Join et Left Outer Join) dans un tMap, sur différentes sources de données, il y a toujours un flux principal (Main) et un ou plusieurs flux de référence (Lookup) connectés au tMap. Tous les enregistrements du flux de référence doivent être chargés avant de traiter chaque enregistrement du flux principal.
DescriptionLoad once : charge une fois (une fois seulement) tous les enregistrements du flux de référence, soit dans la mémoire, soit dans un fichier local, avant de traiter chaque enregistrement du flux principal, si l'option Store temp data est configurée à true. Cette configuration est celle par défaut et est l'option recommandée si vous avez un jeu d'enregistrements volumineux à traiter dans le flux principal, à l'aide d'une jointure entre les deux flux.
Reload at each row : charge à nouveau tous les enregistrements du flux de référence pour chaque enregistrement du flux principal. Généralement, cette option augmente le temps d'exécution du Job, à cause du chargement répété des enregistrements du flux de référence à chaque enregistrement du flux principal. Cependant, cette option est recommandée dans les situations suivantes :
- le flux de données de référence est constamment mis à jour et vous souhaitez charger les dernières données de référence pour chaque enregistrement du flux principal, pour obtenir les données les plus récentes après exécution de la jointure ;
- les lignes sont moins nombreuses dans votre flux principal et vous avez un jeu de données volumineux provenant d'une table de base de données dans le flux de référence. Dans ce cas, l'utilisation de l'option Load once peut causer une erreur de mémoire OutOfMemory. Dans cette situation, l'option Reload at each row est prise en compte.
La procédure de la section suivante présente comment utiliser le modèle Reload at each row.
Reload at each row (cache) : fonctionne comme le modèle Reload at each row, tous les enregistrements du flux de référence sont chargés à nouveau pour chaque enregistrement du flux principal. Cependant, ce modèle ne peut être utilisé avec l'option Store temp data on disk. Les données de référence sont en cache dans la mémoire et, lorsqu'un nouveau chargement survient, seuls les enregistrements qui n'existent pas déjà dans le cache seront chargés, pour éviter deux fois les mêmes enregistrements.
ProcédureCette procédure présente comment utiliser le modèle Reload at each row. Pour de meilleures performances de traitement, il est recommandé d'utiliser des variables globales pour filtrer le flux de données principal et traiter uniquement ce qui doit l'être.
-
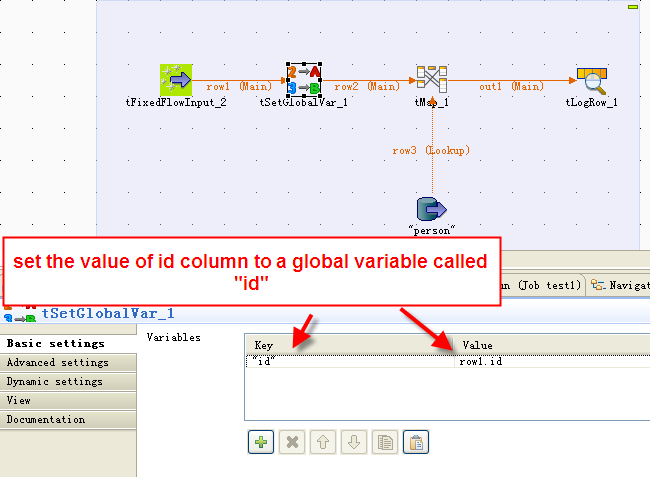
Configurez la valeur d'une colonne du flux principal comme une variable globale (composant tSetGlobalVar ), puis utilisez cette variable dans une condition WHERE dans la requête de lookup, afin de charger uniquement les données correspondantes depuis la table, en vous basant sur une ou plusieurs valeur·s du flux principal, plutôt que de charger les données complètes.
-
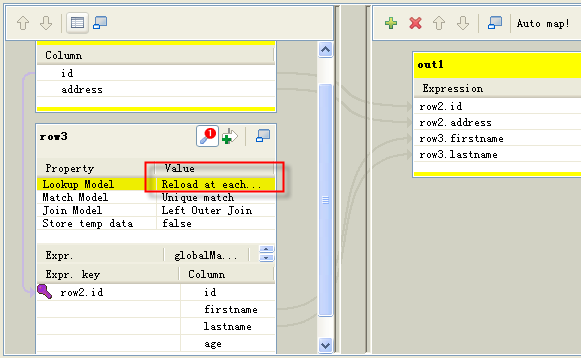
Dans le composant tMap, sélectionnez le modèle Reload at each row pour la colonne Lookup Model :
-
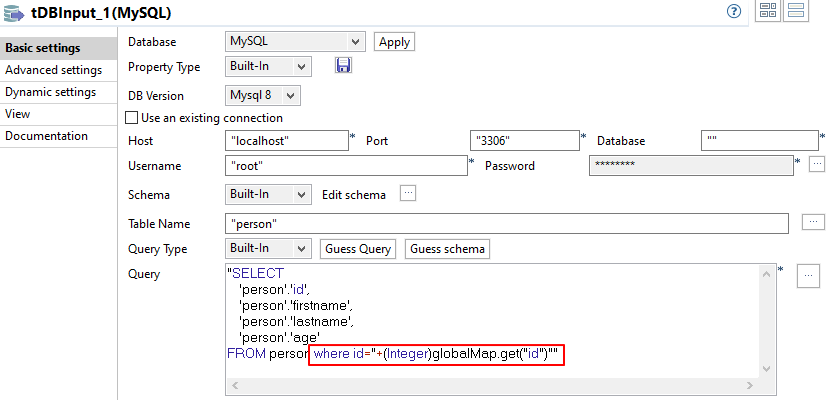
Utilisez la variable globale configurée dans l'étape 1, dans la requête de lookup, pour charger uniquement les données correspondantes depuis la table.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !