
Filtrer des données client·es basées sur des types sémantiques valides et invalides
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion de test.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Téléchargez et extrayez le fichier semantic_filter-customers.zip. Il contient une liste de client·es avec leurs données brutes. Vous pouvez trouver ce fichier en pièce jointe à ce document.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Les fichiers sont stockés dans deux jeux de données de test.
Procédure
-
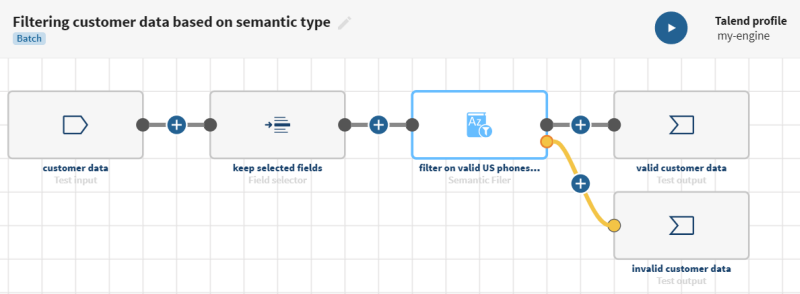
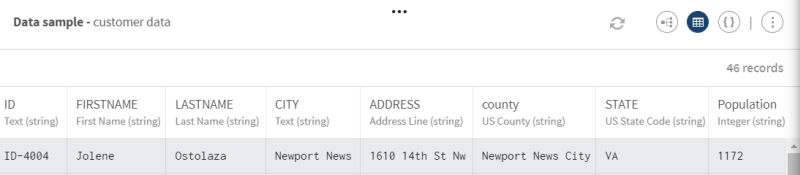
Cliquez sur ADD SOURCE (AJOUTER UNE SOURCE) pour ouvrir le panneau vous permettant de sélectionner vos données source, ici une liste de client·es avec des données brutes (casse incohérente des champs, champs vides, etc.) et des types sémantiques pré-explorés.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
-
Dans l'onglet Configuration :
-
Cliquez sur l'icône
 dans le mode de sélection Simple, pour ouvrir l'arborescence vous permettant de sélectionner et renommer les champs à conserver.
dans le mode de sélection Simple, pour ouvrir l'arborescence vous permettant de sélectionner et renommer les champs à conserver.
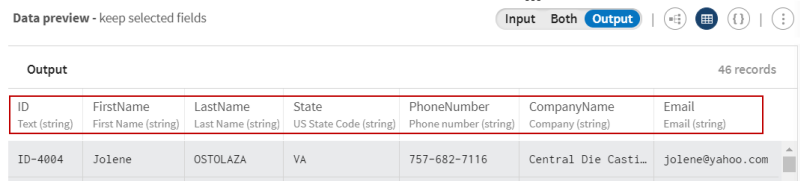
- Sélectionnez les champs suivants dans l'arborescence : ID, FIRSTNAME, LASTNAME, STATE, company_name et EMAIL.
-
Cliquez sur l'icône
 près des champs et renommez-les respectivement en : ID, Firstname, Lastname, State, CompanyName et Email.
près des champs et renommez-les respectivement en : ID, Firstname, Lastname, State, CompanyName et Email.
-
Cliquez sur l'icône
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Examinez la prévisualisation du processeur afin de comparer vos données avant et après la sélection et l'opération de renommage.
-
Cliquez sur le bouton et ajoutez un processeur Semantic filter au pipeline. Le panneau de Configuration s’affiche.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
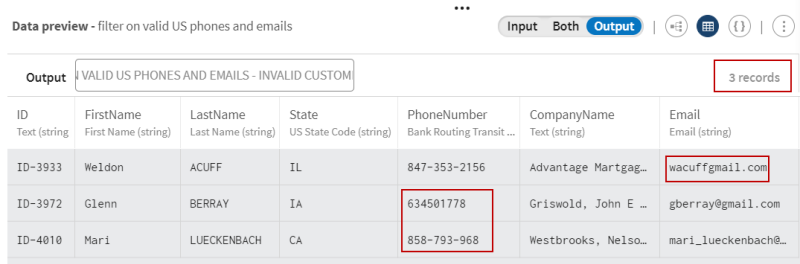
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération de filtre : vous pouvez voir qu'un enregistrement contient une valeur d'adresse e-mail invalide (le caractère @ est manquant) et deux enregistrements ont des valeurs de numéros de téléphone invalides (chiffres manquants) lors du rapprochement avec leurs types sémantiques.
-
Cliquez sur le bouton
 du processeur Semantic filter et cliquez sur l'élément ADD DESTINATION (Ajouter une destination) afin de sélectionner le jeu de données qui contiendra vos données rejetées : les données avec des valeurs invalides.
du processeur Semantic filter et cliquez sur l'élément ADD DESTINATION (Ajouter une destination) afin de sélectionner le jeu de données qui contiendra vos données rejetées : les données avec des valeurs invalides.
Résultats
Votre pipeline est en cours d’exécution. Les données sont filtrées selon les types sémantiques sélectionnés et les flux de sortie sont envoyés vers les destinations définies.
Que faire ensuite
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !