
Traiter des chaînes de caractères relatives à des cultures récoltées
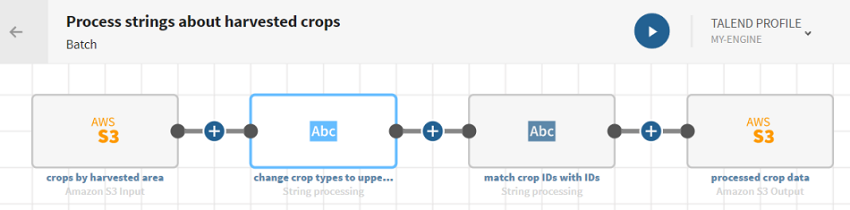
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion Amazon S3.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
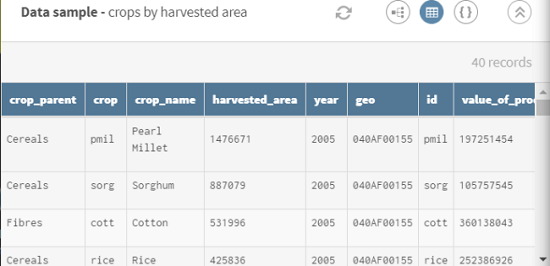
Téléchargez le fichier string-crops.csv. Il contient un jeu de données concernant des cultures récoltées au Mali, ainsi que les types de cultures, la valeur de production, les zones de récolte, etc.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un jeu de données stocké dans le même bucket S3.
Procédure
-
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici les données relatives aux cultures récoltées au Mali en 2005.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Strings au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Strings au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
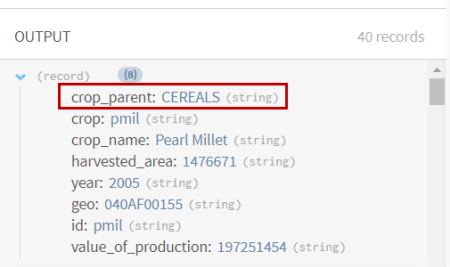
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération.
-
Cliquez sur le bouton et ajoutez un processeur Strings au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
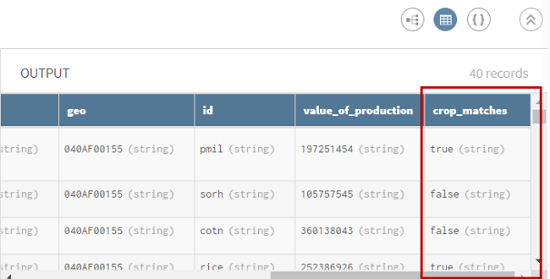
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération. Vous pouvez voir une nouvelle colonne crop_matches dans laquelle les correspondances exactes ont une valeur true et les identifiants sans correspondance ont une valeur false.
Résultats
Votre pipeline est en cours d'exécution, les chaînes de caractères sélectionnées ont été traitées et le flux de sortie est envoyé au bucket S3 indiqué.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !