
Répliquer une liste de prospects et traiter les deux flux de sortie différemment
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion à une base de données.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Téléchargez et extrayez le fichier filter-python-customers.zip. Il contient les données des prospects, notamment leur ID, leur nom ou leur salaire.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un fichier stocké dans Amazon S3 et un fichier stocké dans HDFS.
Procédure
-
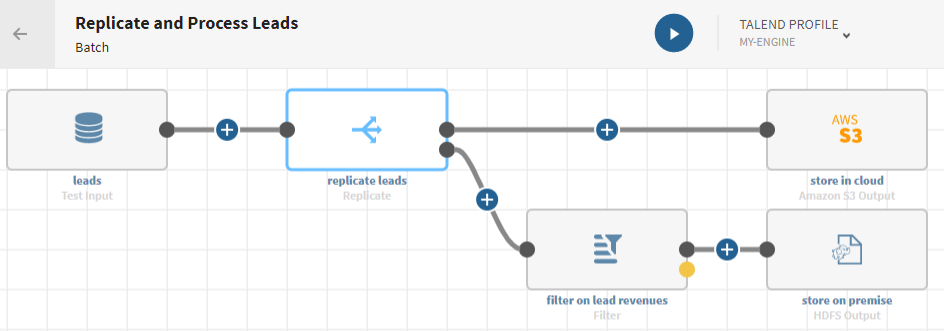
Cliquez sur le bouton
 et ajoutez un processeur Replicate au pipeline. Le flux est dupliqué et le panneau de configuration s'ouvre.
et ajoutez un processeur Replicate au pipeline. Le flux est dupliqué et le panneau de configuration s'ouvre.
-
Cliquez sur près de l'élément ADD DESTINATION (Ajouter une destination) au bas du pipeline et ajoutez un processeur Filter.
-
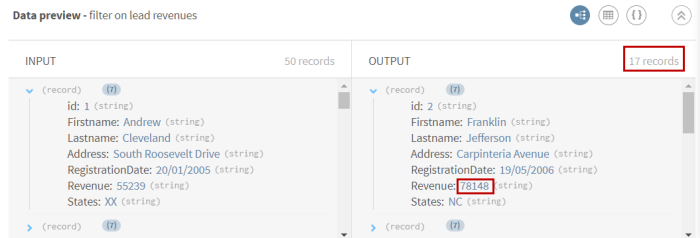
(Facultatif) Consultez l'aperçu du processeur Filter pour voir les données après l'opération de filtre.
Exemple
Résultats
Votre pipeline est en cours d’exécution, les enregistrements sont dupliqués et filtrés et les flux de sortie sont envoyés dans les systèmes cible définis.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !