
Writing data to a cloud data warehouse (Snowflake)
Before you begin
-
You have downloaded the financial_transactions.avro file and you have uploaded it to your Amazon S3 bucket.
- You have reproduced and duplicated the pipeline described in Writing data to a cloud storage (S3) and you will be working on this duplicated pipeline.
- You have created a Remote Engine Gen2 and its run profile from Talend Management Console.
The Cloud Engine for Design and its corresponding run profile come embedded by default in Talend Management Console to help users quickly get started with the app, but it is recommended to install the secure Remote Engine Gen2 for advanced processing of data.
Procedure
-
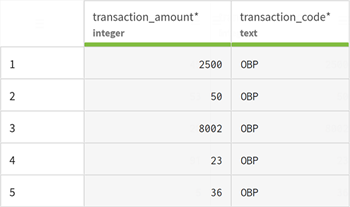
Click View sample to check that your data is valid and can
be previewed.
-
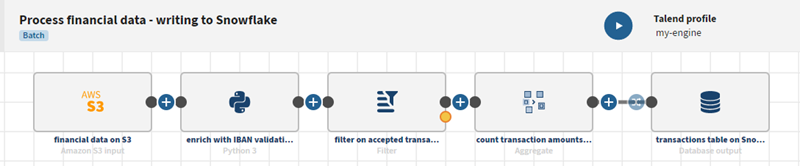
Click Validate to save your dataset. On the
Datasets page, the new dataset is added to the list and can
be used as a destination dataset in your pipeline.
-
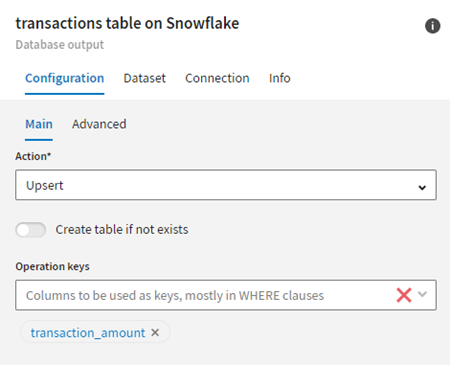
Before executing this pipeline, select Upsert in the
configuration tab of the Snowflake dataset to update and insert the new data in the
Snowflake table. Define the transaction_amount field as the
operation key.
Results
Once your pipeline is executed, the updated data will be visible in the Snowflake database table.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!