
Écrire des données dans un data warehouse Cloud (Snowflake)
Avant de commencer
-
Vous avez récupéré le fichier financial_transactions.avro et vous l'avez chargé dans votre bucket Amazon S3.
- Vous avez reproduit et dupliqué le pipeline décrit dans Écrire des données dans un stockage Cloud (S3) et vous allez travailler sur ce pipeline dupliqué.
- Vous avez créé un Moteur distant Gen2 et son profil d'exécution depuis Talend Management Console.
Le Moteur Cloud pour le design et son profil d'exécution correspondant sont embarqués par défaut dans Talend Management Console pour permettre aux utilisateurs et utilisatrices de prendre l'application en main rapidement, mais il est recommandé d'installer le Moteur distant Gen2 sécurisé pour le traitement avancé des données.
Procédure
-
Cliquez sur View sample (Voir l'échantillon) pour vérifier que vos données sont valides et peuvent être prévisualisées.
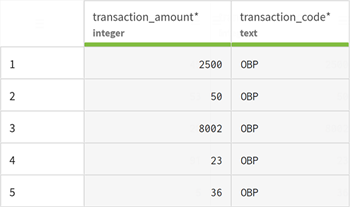
-
Cliquez sur Validate (Valider) pour sauvegarder votre jeu de données. Dans la page Datasets (Jeux de données), le nouveau jeu de données est ajouté à la liste et peut être utilisé comme jeu de données de destination dans votre pipeline.
-
Avant d'exécuter ce pipeline, sélectionnez Upsert dans l'onglet de configuration du jeu de données Snowflake pour mettre à jour et insérer les nouvelles données dans la table Snowflake. Définissez le champ transaction_amount comme clé de l'opération.
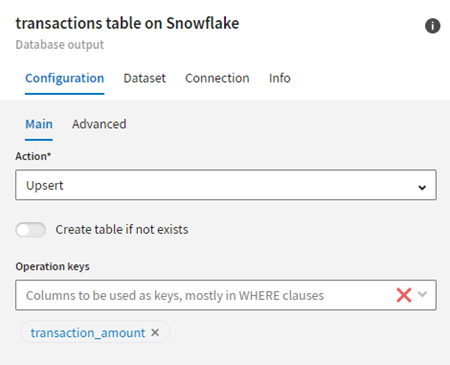
Résultats
Une fois que votre pipeline est exécuté, les données mises à jour sont visibles dans la table de la base de données Snowflake.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !