
Amazon S3との間でデータをロード/アンロード
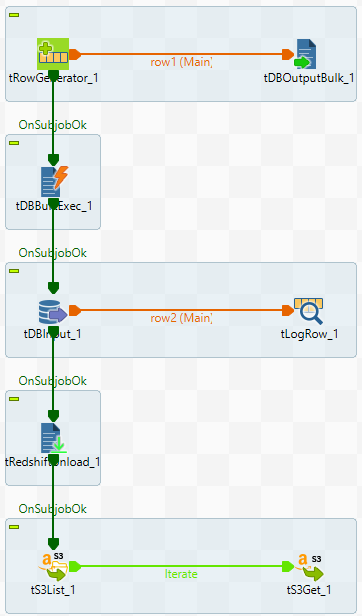
このシナリオでは、区切り付きファイルを生成してS3にアップロードし、S3上のファイルからのデータをRedshiftにロードしてコンソールに表示し、次にデータをRedshiftクラスターのスライスごとにRedshiftからS3上のファイルにアンロードし、最後に、アンロードされたS3上のファイルをリスト表示し、取得するジョブについて説明します。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
前提条件:
次のコンテキスト変数が作成済みで、[Repository] (リポジトリー)ツリービューに保存されていること。コンテキスト変数の詳細は、コンテキストと変数を使用をご覧ください。
-
redshift_host: Redshiftクラスターの接続エンドポイントURL。
-
redshift_port: データベースサーバーのリスニングポート番号。
-
redshift_database: データベースの名前。
-
redshift_username: データベース認証のユーザー名。
-
redshift_password: データベース認証のパスワード。
-
redshift_schema: スキーマの名前。
-
s3_accesskey: Amazon S3にアクセスするためのアクセスキー。
-
s3_secretkey: Amazon S3にアクセスするためのシークレットキー。
-
s3_bucket: Amazon S3バケットの名前。
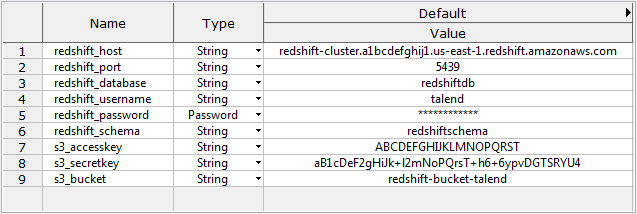
上記スクリーンショットのコンテキスト値はすべて、あくまでも例示用です。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。