
手動で接続を設定
このタスクについて
特定のHadoop設定をインポートする方法がいつでも効率的なことは確かですが、たとえば、インポートできる設定が手元にない場合には、接続を手動でセットアップする必要があります。
手順
-
選択したバージョンに応じてアクティブになったフィールドに情報を入力します。
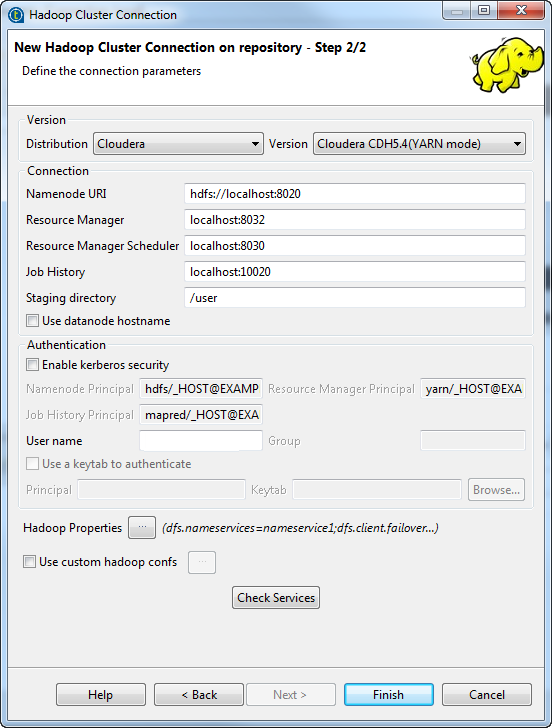
これらのフィールドの中の、[NameNode URI]および[Resource Manager] (リソースマネージャー)フィールドには、選択したディストリビューションに対応するデフォルトの構文とポート番号が自動的に入力されています。使用するHadoopクラスターの設定に応じて必要な部分のみをアップデートする必要があります。各種入力フィールドの詳細は、以下のリストをご覧ください。
 これらのフィールドには、次のようなものがあります。
これらのフィールドには、次のようなものがあります。-
[Namenode URI] (ネームノードURI)
使用するHadoopディストリビューションのネームノードとして使用するマシンのURIを入力します。
ネームノードは、Hadoopシステムのマスターノードです。たとえばApache Hadoopディストリビューションのネームノードとしてmachine1という名前のマシンを選択した場合、URIはhdfs://machine1:portnumberとなります。
WebHDFSを使用している場合、ロケーションはwebhdfs://masternode:portnumberとなります。WebHDFS with SSLはまだサポートされていません。
MapRディストリビューションを使用する場合は、このフィールドのmaprfs:///をそのままにしておくだけで、MapRクライアントが接続の作成時に残りの部分を処理します。ただし、MapRクライアントが正しくインストールされている必要があります。MapRクライアントをインストールして設定する方法は、MapRのドキュメンテーションをご覧ください。
-
Resource Manager (リソースマネージャー):
使用するHadoopディストリビューションのリソースマネージャーサービスとして使用するマシンのURIを入力します。
Hadoopディストリビューションの一部の古いバージョンでは、リソースマネージャーサービスの代わりにジョブトラッカーサービスの場所を設定しなければならない場合があります。
その場合は、[Resourcemanager scheduler] (リソースマネージャースケジューラー)のアドレスなど、関連サービスのアドレスをさらに設定する必要があります。この接続をtHiveConnectionなどビッグデータに関連するコンポーネントに使用すると、[Advanced settings] (詳細設定)ビューでMap/Reduceの計算やYARNの[ApplicationMaster] (アプリケーションマスター)にメモリを割り当てることができます。リソースマネージャー、そのスケジューラー、およびアプリケーションマスターの詳細は、該当するディストリビューションのYARNに関するドキュメンテーション (英語のみ)をご覧ください。
-
[Job history] (ジョブ履歴):
使用するHadoopクラスターのジョブ履歴サーバーの場所を入力します。これにより、現在のジョブのメトリックス情報がそのJobHistoryサーバーに保存されます。
-
[Staging directory] (ステージングディレクトリー):
プログラムの実行で作成された一時ファイル用Hadoopクラスターで定義したこのディレクトリーを入力します。一般的には、このディレクトリーはディストリビューションのyarn-site.xmlやmapred-site.xmlなどの設定ファイル内にあるyarn.app.mapreduce.am.staging-dirプロパティの下にあります。
-
[Use datanode hostname] (データノードホスト名を使用):
このチェックボックスをオンにして、これらのホスト名によるデータノードへのアクセスをジョブに許可します。これは、実際にはdfs.client.use.datanode.hostnameプロパティをtrueに設定しています。この接続がS3Nファイルシステムに接続するジョブによって使用される場合は、このチェックボックスをオンにする必要があります。
-
[Enable Kerberos security] (Kerberosセキュリティを有効化):
Kerberosセキュリティを実行しているHadoopディストリビューションにアクセスする場合は、このチェックボックスをオンにし、表示されるフィールドにネームノードとしてKerberosのプリンシパル名を入力します。
これらのプリンシパルはディストリビューションの設定ファイルの中にあります。たとえばCDH4ディストリビューションでは、リソースマネージャーのプリンシパルはyarn-site.xmlファイルで設定され、ジョブ履歴のプリンシパルはmapred-site.xmlファイルで設定されています。
ログインにkeytabファイルが必要な場合は、[Use a keytab to authenticate] (認証にkeytabを使用)チェックボックスをオンにします。keytabファイルには、Kerberosのプリンシパルと暗号化されたキーのペアが含まれています。使用するプリンシパルを[Principal] (プリンシパル)フィールドに入力し、keytabファイルへのパスを[Keytab]フィールドに入力します。
keytabが有効なジョブは、プリンシパルに任命されたユーザーでなくても実行できますが、使用するkeytabファイルの読み取り権限が必要です。たとえば、user1というユーザー名でジョブを実行し、使用するプリンシパルがguestの場合、user1に使用するkeytabファイルの読み取り権限があることをご確認ください。
-
MapR cluster V4.0.1以降に接続する予定で、クラスターのMapRチケットセキュリティシステムが有効の場合は、[Force MapR Ticket Authentication] (MapRチケット認証を強制)チェックボックスをオンにし、以下のパラメーターを定義する必要があります。
- [Password] (パスワード)フィールドに、ユーザーが認証に使用するパスワードを指定します。
MapRセキュリティチケットがMapRによってこのユーザーのために生成され、設定しているジョブを実行するマシンに保存されます。
- [Cluster name] (クラスター名)フィールドに、このユーザー名を使用して接続するMapRクラスターの名前を入力します。
このクラスター名は、クラスターの/opt/mapr/confに保存されているmapr-clusters.conf ファイル内にあります。
- [Ticket duration] (チケットの有効期間)フィールドに、チケットが有効となる時間の長さ(秒単位)を入力します。
- [Launch authentication mechanism when the Job starts] (ジョブの開始時に認証メカニズムを起動する) チェックボックスをオンのままにしておきます。これは、この接続を使用するジョブが実行を開始する時に現在のセキュリティ設定を考慮するよう指定するためです。
MapRクラスターのデフォルトセキュリティ設定が変更された場合は、このカスタムセキュリティ設定を考慮するように接続を設定する必要があります。
MapRは、クラスターの/opt/mapr/confに保存されているmapr.login.confファイル内に、そのセキュリティ設定を指定します。この設定ファイルと、設定ファイルが背後で使用するJavaサービスの詳細は、MapRのドキュメンテーションおよびJAASをご覧ください。
次の手順に従って設定を行います。
- このmapr.login.confファイルで何が変更されたかを確認します。
関連情報は、MapRクラスターの管理者または開発者から入手できます。
- MapR設定ファイルのロケーションがクラスター内の別の場所に変更された場合、つまり、MapRのホームディレクトリーが変更された場合は、[Set the MapR Home directory] (MapRのホームディレクトリーを設定する)チェックボックスをオンにし、新しいホームディレクトリーを入力します。それ以外の場合は、このチェックボックスをオフにしたままにしておきます。この場合は、デフォルトのホームディレクトリーが使用されます。
- mapr.login.confファイル内で使用するログインモジュールが変更された場合は、[Specify the Hadoop login configuration] (Hadoopログイン設定の指定)チェックボックスをオンにし、mapr.login.confファイルから呼び出すモジュールを入力します。それ以外の場合は、このチェックボックスを外したままにしておきます。この場合は、デフォルトのログインモジュールが使用されます。
たとえばhadoop_kerberosモジュールを呼び出すにはkerberosと入力し、hadoop_hybridモジュールを呼び出すにはhybridと入力します。
- [Password] (パスワード)フィールドに、ユーザーが認証に使用するパスワードを指定します。
-
[User name] (ユーザー名):
使用するHadoopディストリビューションのユーザー認証名を入力します。
このフィールドを空白のままにすると、Studioはクライアントへのログインに使用している名前を使ってHadoopディストリビューションにアクセスします。たとえば[Company]という名前でログインしているWindowsマシンでStudioを使用している場合、実行時にも[Company]という認証名が使用されます。
-
Group (グループ):
認証されたユーザーが所属するグループ名を入力します。
このフィールドは、使用しているHadoopのディストリビューションによっては、利用できないこともあります。
-
[Hadoop properties] (Hadoopのプロパティ):
使用するHadoopディストリビューションの設定をカスタマイズする必要がある場合は、[...]ボタンをクリックしてプロパティテーブルを開き、カスタマイズするプロパティを追加します。その後、実行時にStudioがHadoopのエンジンに使用するデフォルトのプロパティが、カスタマイズした設定に上書きされます。
このテーブルで設定されたプロパティは、現在のHadoop接続に基づいて作成できる子接続に継承され再利用されます。
Hadoopのプロパティの詳細は、Apache Hadoopに関するドキュメンテーション (英語のみ)か、使用するHadoopディストリビューションのドキュメンテーションをご覧ください。たとえば、このページ (英語のみ)にはデフォルトのHadoopプロパティがいくつか記載されています。
このプロパティテーブルの活用方法の詳細は、再利用可能なHadoopのプロパティの設定 (英語のみ)をご覧ください。
- [Use Spark Properties] (Sparkプロパティの使用): [Use Spark properties] (Sparkプロパティの使用)チェックボックスをオンにして、プロパティテーブルを開き、使用するSparkの設定に固有のプロパティまたはプロパティspark-defaults.confを追加します。
-
ディストリビューションにMicrosoft HD Insightを使用する場合、前述のパラメーターの代わりに、HD Insightクラスターには[WebHCat configuration] (WebHCat設定)、HD Insightクラスターの認証情報には[HDInsight configuration] (HDInsight設定)、および[Window Azure Storage]の設定を行う必要があります。
WebHCatの設定
使用するMicrosoft HD Insightクラスターのアドレスと認証情報を入力します。たとえば、アドレスはyour_hdinsight_cluster_name.azurehdinsight.netとなり、Azureアカウントの認証情報は次のようになります: ychen。Studioはこのサービスを使ってジョブをHD Insightクラスターに送信します。
[Job result folder] (ジョブ結果保存フォルダー)フィールドに、使用するAzure Storageでのジョブの実行結果を保存するロケーションを入力します。
[HDInsight configuration] (HDInsightの設定)
- [Username] (ユーザー名)は、クラスターの作成時に定義されたものです。これは、クラスターの[SSH + Cluster] (SSH + クラスター)ログインブレードで確認できます。
- [Password] (パスワード)は、このクラスターの認証でHDInsightクラスターを作成する時に定義します。
[Windows Azure Storage configuration] (Windows Azure Storageの設定)
使用するAzure StorageアカウントかADLS Gen2アカウントのアドレスと認証情報を入力します。この設定では、ビジネスデータを読み書きする場所は定義せず、ジョブをデプロイする場所のみ定義します。
[Primary storage] (プライマリーストレージ)ドロップダウンリストから、使用するストレージを選択します。
TLSでストレージを保護する場合は、[use secure connection (TLS)] (セキュア接続(TLS)を使用)チェックボックスをオンにします。
[Container] (コンテナー)フィールドに、使用するコンテナーの名前を入力します。利用可能なコンテナーは、使用するAzure StorageアカウントのBlobブレードで確認できます。
[Deployment Blob] (デプロイメントBlob)フィールドに、このAzure Storageアカウントで現在のジョブとその依存ライブラリーを保存する場所を入力します。
[Hostname] (ホスト名)フィールドに、https://部分を含まないAzure StorageアカウントのプライマリーBlobサービスエンドポイントを入力します。このエンドポイントは、このストレージアカウントの[Properties] (プロパティ)ブレードにあります。
[Username] (ユーザー名)フィールドに、使用するAzure Storageアカウントの名前を入力します。
[Password] (パスワード)フィールドに、使用するAzure Storageアカウントのアクセスキーを入力します。このキーは、このストレージアカウントの[Access keys] (アクセスキー)ブレードにあります。
- Cloudera V5.5+をお使いの場合は、[Use Cloudera Navigator] (Cloudera Navigatorの使用)チェックボックスをオンにして、ディストリビューションのCloudera ナビゲーターが、コンポーネント間のスキーマの変更を含め、ジョブ来歴をコンポーネントレベルまでトレースできるようにすることが可能です。
続いて[...]ボタンをクリックして[Cloudera Navigator Wizard] (Cloudera Navigatorウィザード)ウィンドウを開き、以下のパラメーターを定義する必要があります。
-
[Username] (ユーザー名)および[Password] (パスワード): Cloudera Navigatorへの接続に使用する認証情報です。
-
[URL]: Cloudera Navigatorの接続先を入力します。
-
[Metadata URL] (メタデータURL): ナビゲーターメタデータの場所を入力します。
-
[Client URL] (クライアントURL): デフォルト値をそのままにしておきます。
-
[Autocommit] (自動コミット): このジョブの実行の最後にCloudera Navigatorが現在のジョブの来歴を生成するよう設定するには、このチェックボックスをオンにします。
このオプションを指定すると、Cloudera NavigatorはHDFSファイルとディレクトリー、HiveクエリーまたはPigスクリプトなど、利用可能なすべてのエンティティの来歴を生成するように強制されるため、ジョブの実行速度の低下を招くことから本番環境には推奨されません。
- [Die on error] (エラー発生時に強制終了): Cloudera Navigatorへの接続が失敗した時にジョブの実行を停止するには、このチェックボックスをオンにしてください。それ以外の場合は、解除してジョブが実行を継続できるようにしてください。
- [Disable SSL] (SSLの無効化): ジョブがSSL検証プロセスなしでCloudera Navigatorに接続するように指定するには、このチェックボックスをオンにします。
この機能は、ジョブのテストを容易にするためのものですが、プロダクションクラスターで使用することは推奨されません。
設定が終了したら、[Finish] (終了)をクリックして設定を確定します。
-
-
-
[Finish] (終了)をクリックして変更を確定し、ウィザードを閉じます。
新しくセットアップしたHadoopの接続は、[Repository] (リポジトリー)ツリービューの[Hadoop cluster]フォルダーの下に表示されます。この接続には、同じHadoopディストリビューションの下にあるモジュールに接続を作成しない限り、サブフォルダーはありません。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。