
カラムセット分析を確定および実行
このカラムセット分析を実行する前に、インジケーターの設定、データフィルター、分析パラメーターを定義する作業が残っています。
始める前に
手順
-
[Analysis Parameters] (分析パラメーター)ビューで、次を実行します。
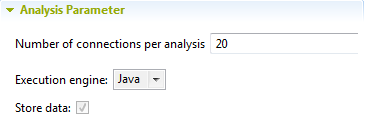
- [Number of connections per analysis] (分析ごとの接続数)フィールドで、分析ごとに、選択したデータベースへの接続に対して許可する同時接続数を設定します。
この数値はデータベースの利用可能リソース、つまりデータベースがサポートできる同時接続数に基づいて設定します。
- [Execution engine] (実行エンジン)リストから、分析の実行に使用したいエンジン(JavaまたはSQL)を選択します。
- Javaエンジンを選択した場合、[Store data] (データを保存)チェックボックスはデフォルトでオンになっており、オフにすることはできません。分析が実行されると、いつでもプロファイリング結果をローカルで使用できるため、ビューを通じて結果をドリルダウンできます。
Javaエンジンを使用して分析を実行すると、すべてのデータが取得され、ローカルに保存された時にディスク容量が使用されます。空き容量を作成する場合は、Talend-Studio/workspace/project_name/Work_MapDBのメインのTalend Studioディレクトリー内に保存されているデータを削除できます。
- SQLエンジンを選択した場合は、[Store data] (データを保存)チェックボックスを使い、分析されたデータをローカルに保存してビューでアクセスするかどうか決定できます。情報メモ注: 分析しているデータが非常に大きい場合は、分析計算の最後に結果を保管しないように、[Store data] (データの保管)チェックボックスをオフにしておくことをお勧めします。
- Javaエンジンを選択した場合、[Store data] (データを保存)チェックボックスはデフォルトでオンになっており、オフにすることはできません。分析が実行されると、いつでもプロファイリング結果をローカルで使用できるため、ビューを通じて結果をドリルダウンできます。
- [Number of connections per analysis] (分析ごとの接続数)フィールドで、分析ごとに、選択したデータベースへの接続に対して許可する同時接続数を設定します。
-
分析を保存し、F6を押して実行します。
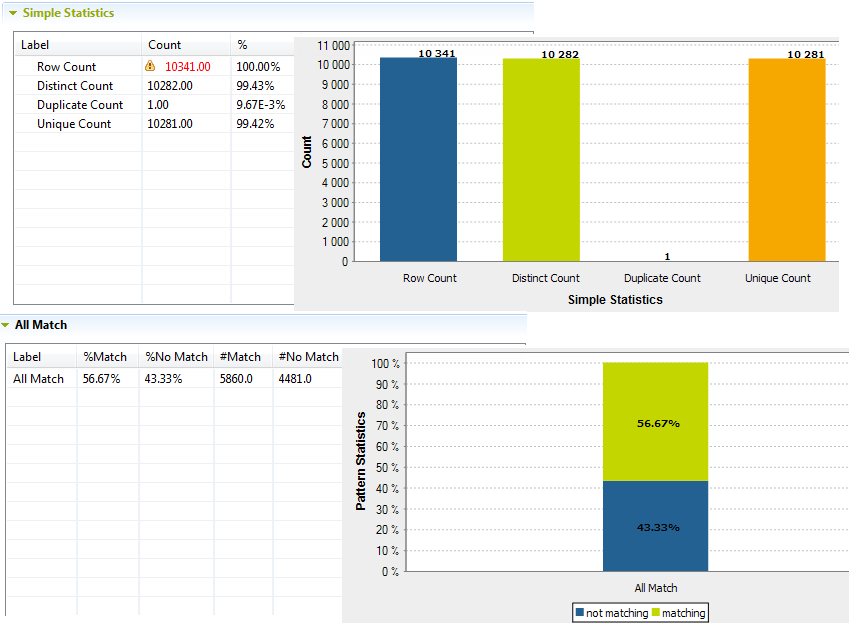
分析エディターが[Analysis Results] (分析結果)ビューに切り替わり、分析結果がテーブルとグラフィックで表示されます。グラフ結果では、各カラム個別の値ではなく、分析済みカラムの完全レコードに関するシンプル統計が得られます。
分析するカラムのセットのコンテンツに一致させるためにパターンを使う場合は、使用するパターンの総計に対して一致結果と非一致結果を表すグラフが表示されます。
次のタスク
情報メモ制約事項: [All Match] (すべて一致)テーブルは、Javaエンジンを使用して分析を実行する場合のみ使用できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。