
カラム分析を確定および実行
分析するカラムを定義し、インジケーターを設定したら、分析するデータにフィルターを適用し、カラム分析の実行に使用するエンジンを決めます。
始める前に
- 分析エディターでカラム分析が開いていること。
- カラム分析でシステムインジケーターまたは事前定義済みインジケーターを設定していること。
- データクオリティに必要なSQLエクスプローラーライブラリーをStudioにインストール済みであること。
手順
-
[Analysis Parameters] (分析パラメーター)ビューで、次の手順に従います。
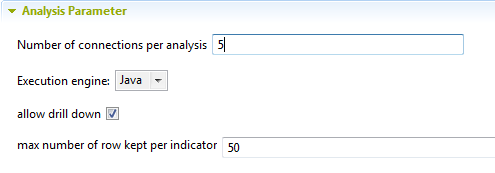
-
分析を保存し、F6を押して実行します。
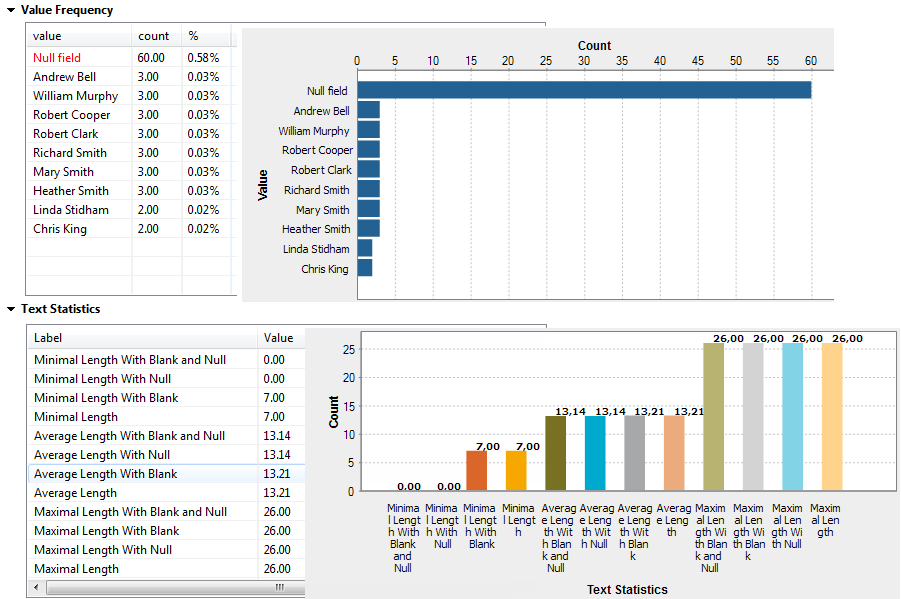
エディターが[Analysis Results] (分析結果)ビューに切り替わります。SQLエンジンを使用している場合は、分析では複数のインジケーターが並列して実行され、分析が進行中でも、チャート内の結果は更新されます。以下は、fullnameカラムの頻度とテキスト統計を表すグラフィックです。
 以下は、emailカラムのパターン頻度とパターン低頻度統計を表すグラフィックです。
以下は、emailカラムのパターン頻度とパターン低頻度統計を表すグラフィックです。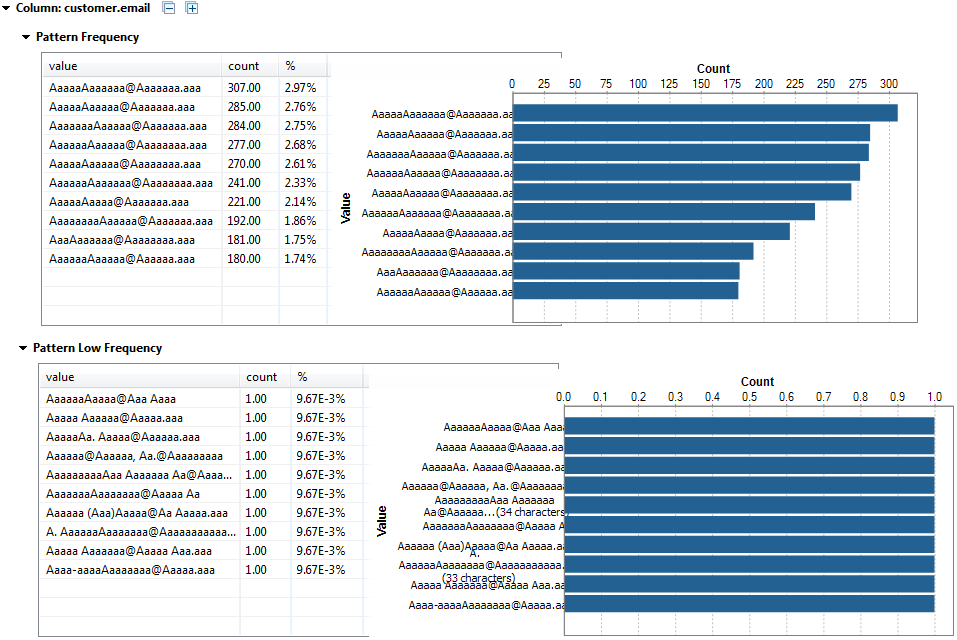 テーブル内のパターンでは、aとAを使ってメールの値を表します。各パターンには30文字まで使用できます。文字の合計数が30を超えると、パターンは次のように表されます: aaaaaAAAAAaaaaaAAAAAaaaaaAAAAA...<合計文字数>。テーブル内のパターン上にマウスポインターを置くと、元の値が表示されます。これらのインジケーターの詳細は、[Pattern frequency statistics] (パターン頻度統計) (英語のみ)をご覧ください。以下は、total_salesカラムの集計統計を表すグラフィックです。
テーブル内のパターンでは、aとAを使ってメールの値を表します。各パターンには30文字まで使用できます。文字の合計数が30を超えると、パターンは次のように表されます: aaaaaAAAAAaaaaaAAAAAaaaaaAAAAA...<合計文字数>。テーブル内のパターン上にマウスポインターを置くと、元の値が表示されます。これらのインジケーターの詳細は、[Pattern frequency statistics] (パターン頻度統計) (英語のみ)をご覧ください。以下は、total_salesカラムの集計統計を表すグラフィックです。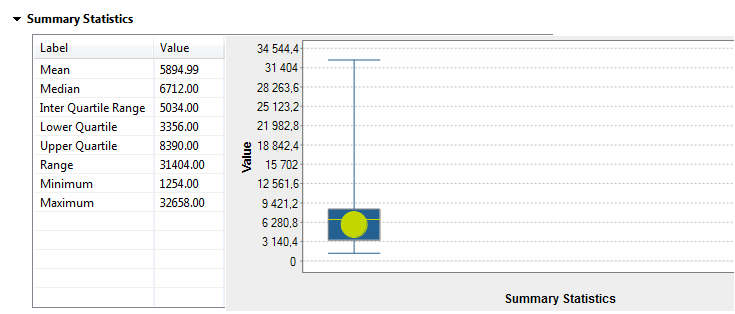 これらのインジケーターの詳細は、集計統計 (英語のみ)をご覧ください。また、以下はtotal_salesカラムの指標およびベンフォードの法則度数統計を表すグラフィックです。
これらのインジケーターの詳細は、集計統計 (英語のみ)をご覧ください。また、以下はtotal_salesカラムの指標およびベンフォードの法則度数統計を表すグラフィックです。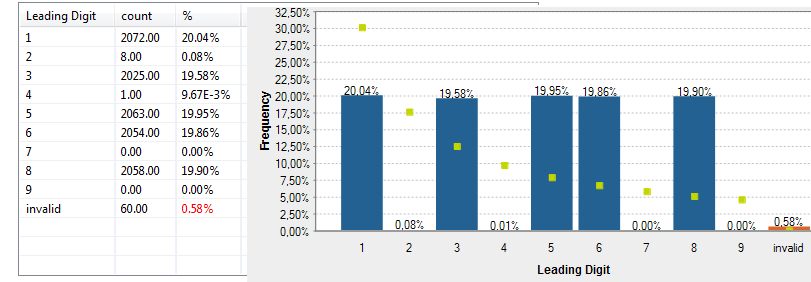 不正会計と経費のインジケーターとして通常使用されるベンフォードの法則度数統計の詳細は、不正の検出 (英語のみ)をご覧ください。
不正会計と経費のインジケーターとして通常使用されるベンフォードの法則度数統計の詳細は、不正の検出 (英語のみ)をご覧ください。
タスクの結果
Javaエンジンを選択すると、システムではJava正規表現が最初に検索され、何も見つからないと、SQL正規表現が検索されます。
SQLエンジンを使ってこの分析を実行した場合、インジケーターを右クリックし、リストから[View executed query] (実行したクエリーを表示する)オプションを選択すると、付加した各インジケーターに対して実行したクエリーを確認できます。ただし、Javaエンジンを使用するとSQLクエリーにアクセスできなくなり、このオプションをクリックすると警告メッセージが表示されます。
Javaエンジンの詳細は、JavaエンジンまたはSQLエンジンの使用 (英語のみ)をご覧ください。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。