- Big Data Platform
- Cloud API Services Platform
- Cloud Big Data Platform
- Cloud Data Fabric
- Cloud Data Management Platform
- Data Fabric
- Data Management Platform
- Data Services Platform
- MDM Platform
- Real-Time Big Data Platform
カラム分析の結果に対して既製ジョブを生成できます。このジョブは、有効/無効な行またはその両方の行を再取得し、それらを出力ファイルまたはデータベースに書き込みます。
始める前に
パターンを使用するカラム分析が作成され実行されていること。
手順
-
パターンを使用するカラム分析を作成するには、 分析するカラムを定義およびカラム分析への正規表現またはSQLパターンの追加で説明されている手順に従います。
-
カラム分析を実行します。
-
[Analysis Results] (分析結果)ビューで、分析済みカラムの名前の下の[Pattern Matching] (パターンマッチング)をクリックします。
パターンマッチングの生成グラフと、一致結果の詳細を示すテーブルが表示されます。
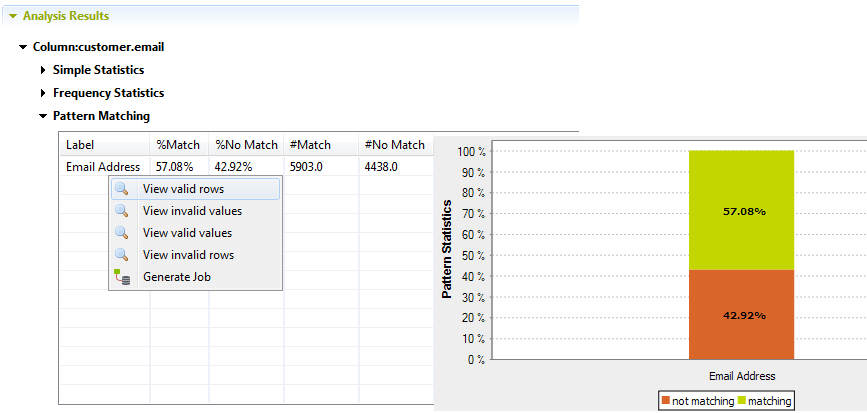
-
[Pattern Matching] (パターンマッチング)テーブルのパターンの行を右クリックして、[Generate jobs] (ジョブを生成)を選択します。
[Job Selector] (ジョブセレクター)ダイアログボックスが表示されます。
特定のデータベースで定義されているパターンを使用してカラムを分析すると、複数のELTジョブを生成できるようになります。
Javaまたはデフォルトの言語で定義されているパターンを使用してカラムを分析すると、1つのETLジョブを生成できるようになります。
-
ダイアログボックスで、次を選択します。
| オプション |
操作 |
|---|
| [generate an ELT job to get only valid rows] (有効行のみ取得するELTジョブを生成) |
抽出、ロード、変換プロセスを使用するジョブを生成し、出力ファイルに分析済みカラムの有効な行を書き込みます。 このオプションはAmazon Redshiftデータベースには使用できません。
|
| [generate an ELT job to get only invalid rows] (無効行のみ取得するELTジョブを生成) |
抽出、ロード、変換プロセスを使用するジョブを生成し、出力ファイルに分析済みカラムの無効な行を書き込みます。 このオプションはAmazon Redshiftデータベースには使用できません。
|
| [generate an ETL job to handle rows] (行を処理するETLジョブを生成) |
抽出、変換、ロードプロセスを使用するジョブを生成し、出力ファイルに分析済みカラムの有効/無効な行を書き込みます。 |
この例では、[generate an ETL job to handle rows] (行を処理するETLジョブを生成)オプションを選択して、2つの個別の出力ファイルに有効および無効なメール行を出力するジョブを生成します。
-
ダイアログボックスで、[Finish] (終了)をクリックして次のステップに進みます。
生成されたジョブでIntegrationパースペクティブが開きます。
- オプション:
必要であれば、さまざまな出力コンポーネントを使い、異なるタイプのファイルやデータベースにある有効行や無効行を再取得します。
-
ジョブを保存し、F6を押して実行します。
分析済みカラムの有効および無効なメール行が、定義された出力ファイルに書き込まれます。
取得されるファイルの結果は、ETLモードまたはELTモードによって異なる場合があります。ETLモードではJava正規表現に対してデータが取得されますが、ELTモードでは適切なデーターベースの正規表現に対してデータが取得されます。正規表現エンジンは、JavaとDBMSでは動作が異なるため、結果が異なる場合があります。パターンエディターで異なる正規表現を定義している場合は、相違はさらに大きくなります。