
tMapルックアップモデル
ニーズに応じて最適なモデルを選択できるように、この記事では各モデルについて詳しく説明します。
さまざまなタイプのビジネス要件に合わせて、3種類のルックアップロードモデルが提供されています。- 一括ロード
- 行ごとにリロード
- 行ごとにリロード(キャッシュ)
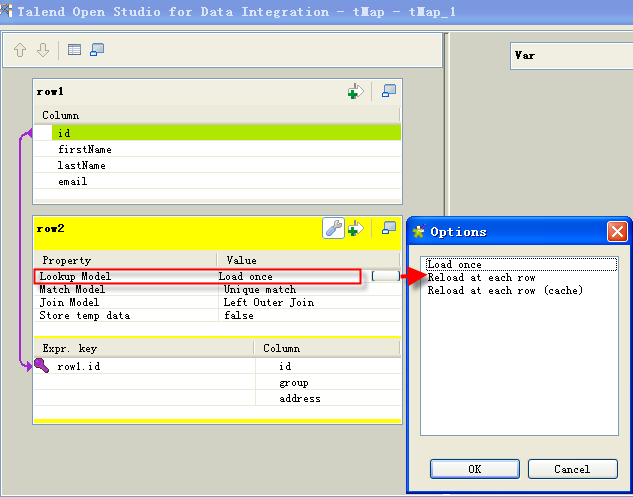
tMap内で異なるデータソースの間に結合([Inner Join] (内部結合)と[Left Outer Join] (左外部結合)を含む)を実装する時は、常にメインフローが1つだけあり、tMapに接続された1つ以上のルックアップフローがあります。ルックアップフローのレコードはすべて、メインフローの各レコードを処理する前にロードする必要があります。
説明[Load once] (一括ロード): メインフローの各レコードを処理する前に、[Store temp data] (一時データ格納)オプションがTrueに設定されている場合、メモリ内またはローカルファイル内のルックアップフローから、すべてのレコードを1回で(1回限り)ロードします。これが結合のデフォルト設定です。ルックアップフローへの結合を使用して処理するメインフローの中に大きなレコードのセットがある場合には、これが最適なオプションとなります。
[Reload at each row] (行ごとにリロード): メインフローのレコードごとにルックアップフローの全レコードが再びロードされます。各メインフローレコードに対してルックアップフローが繰り返しロードされるため、一般にこのオプションではジョブ実行時間が長くなります。ただし、このオプションは以下の2つの状況では優先すべきです。
- ルックアップデータフローが絶えずアップデートされる状況にあり、結合実行後に最新のデータを取得するために、メインフローの各レコード用に最新のルックアップデータをロードしたい。
- メインフローの行数が少なく、ルックアップフローのデータベーステーブルから取得した大きなデータセットがある。[Load once] (一括ロード)オプションを使用するとOutOfMemory例外が発生するおそれがあります。この状況では、[Reload at each row] (行ごとにリロード)オプションが考慮されます。
次のセクションの手順では、[Reload at each row] (行ごとにリロード)モデルを使用する方法について説明します。
[Reload at each row (cache)] (行ごとにリロード - キャッシュ): このモデルは[Reload at each row] (行ごとにリロード)モデルと同じように機能し、ルックアップフローのすべてのレコードはメインフローの各レコードのために再びロードされます。ただし、このモデルは[Store temp data on disk] (一時データをディスクへ保管)オプションには使用できません。ルックアップデータはメモリにキャッシュされており、新たなロードが発生すると、キャッシュにまだ入っていないレコードのみがロードされます。これは、同じレコードを2度ロードすることを避けるためです。
手順この手順では、[Reload at each row] (行ごとにリロード)モデルを使用する方法について説明します。処理のパフォーマンスを向上させるには、メインデータフローをフィルタリングし、処理が必要なもののみを処理するためにグローバル変数を使用することをお勧めします。
-
メインフローの1つのカラムの値をグローバル変数(tSetGlobalVarコンポーネント)に設定し、データ全体をロードするのではなく、メインフローの1つまたは複数の値に基づいてテーブルから一致したデータのみをロードするために、ルックアップクエリーのWHERE条件でこの変数を使用します。
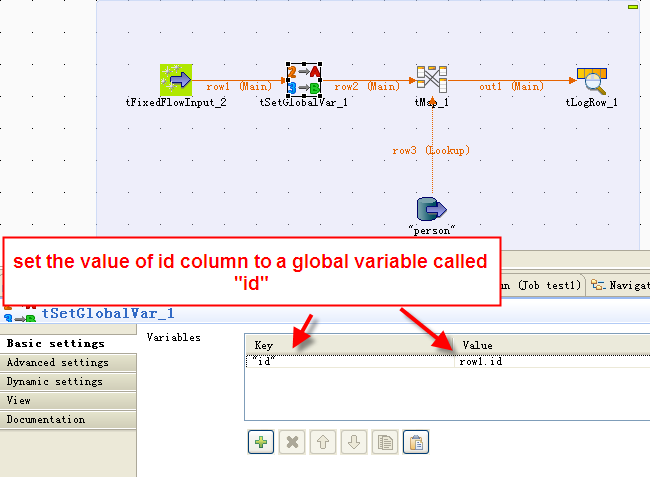
-
tMapコンポーネントで、[Lookup Model] (ルックアップモデル)カラムに[Reload at each row] (行ごとにリロード)モデルを選択します。
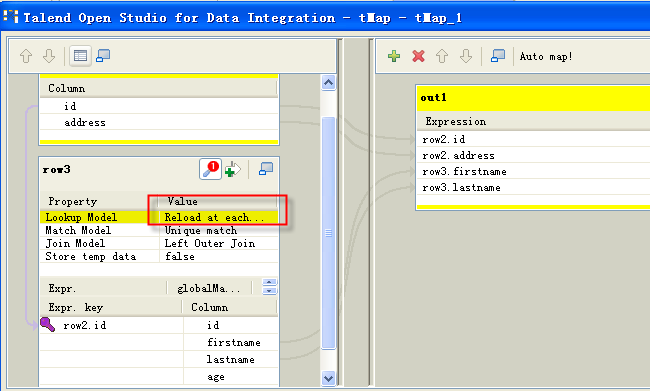
-
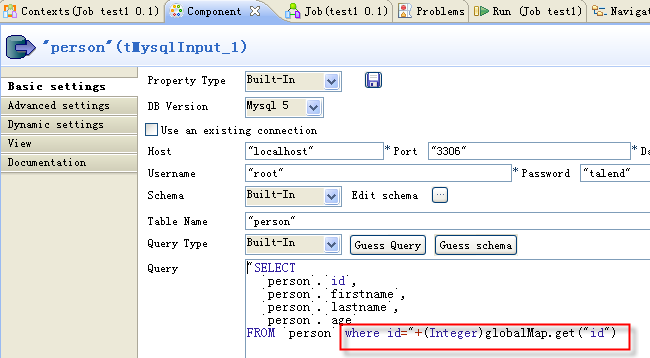
ステップ1で設定したグローバル変数をルックアップクエリーで使用して、一致したデータのみをテーブルからロードします。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。