
マッチングルールの定義
手順
-
tMatchGroupの基本設定で[Preview] (プレビュー)をクリックして設定ウィザードを開き、マッチングキーとサバイバーシップ機能を定義します。
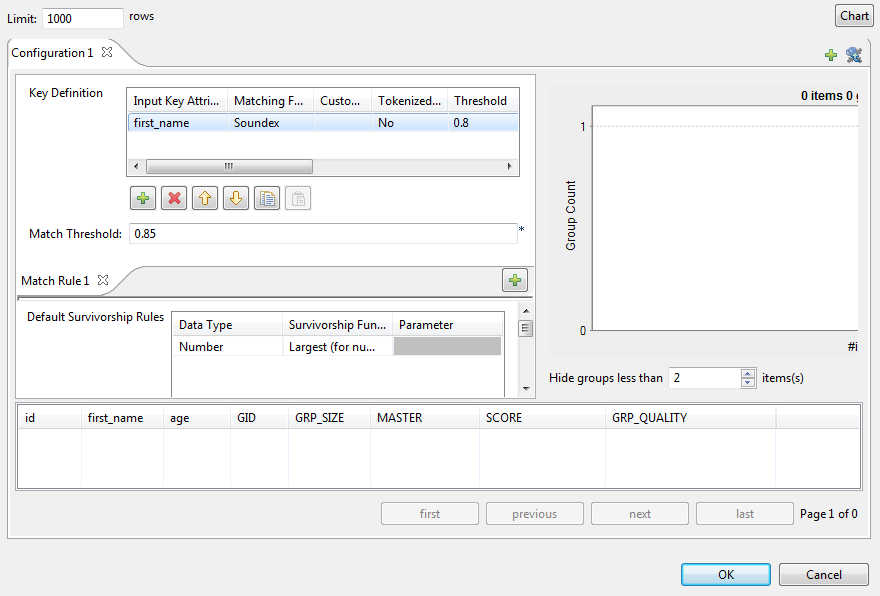 設定ウィザードを使用して、Studio Talendで作成およびテストし、リポジトリーに保存した一致ルールをインポートし、マッチングジョブで使用できます。詳細は、マッチングルールをStudio Talendリポジトリーからインポートをご覧ください。コンポーネントの基本設定で同じ種類のマッチングアルゴリズムを選択し、構成ウィザードで定義することが重要です。それ以外の場合、ジョブは2つのアルゴリズム間で互換性のないパラメーターのデフォルト値で実行されます。
設定ウィザードを使用して、Studio Talendで作成およびテストし、リポジトリーに保存した一致ルールをインポートし、マッチングジョブで使用できます。詳細は、マッチングルールをStudio Talendリポジトリーからインポートをご覧ください。コンポーネントの基本設定で同じ種類のマッチングアルゴリズムを選択し、構成ウィザードで定義することが重要です。それ以外の場合、ジョブは2つのアルゴリズム間で互換性のないパラメーターのデフォルト値で実行されます。 -
ウィザードの[Chart] (チャート)ボタンをクリックして、定義済みの設定でジョブを実行し、結果をウィザードに直接表示します。
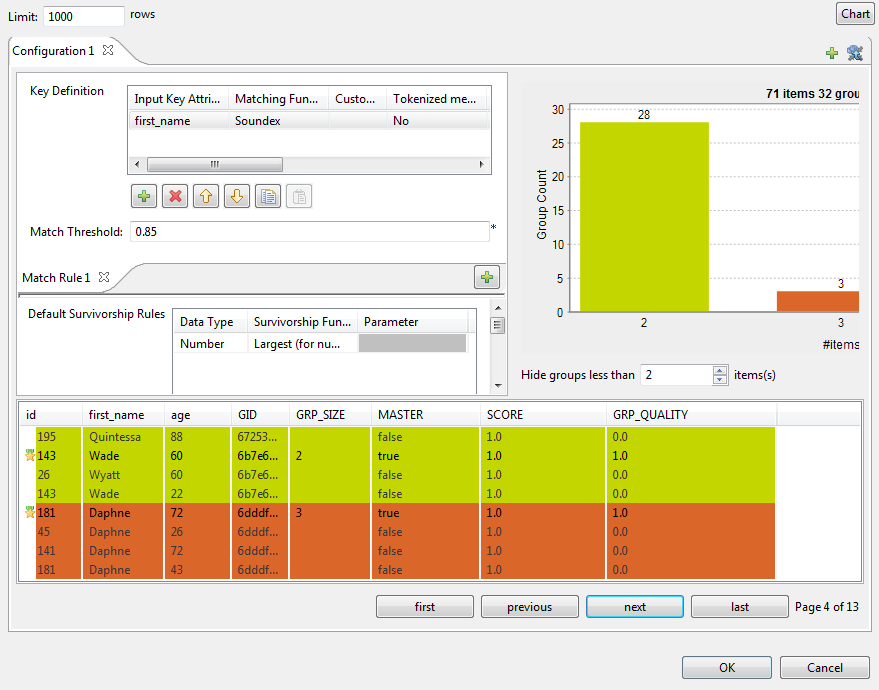 マッチングチャートは、分析されたデータの重複の全体図が表示されます。マッチングテーブルには各グループの項目の詳細が示され、マッチングチャートの色に基づいてグループが色分けされます。また、レコードのうち、マスターレコードはtrueと表示されます。各グループ内のマスターレコードは、2つの類似するレコードを音声アルゴリズムとサバイバーシップルールに従ってマージした結果です。マスターレコードは、入力データ内に存在しない新しいレコードです。
マッチングチャートは、分析されたデータの重複の全体図が表示されます。マッチングテーブルには各グループの項目の詳細が示され、マッチングチャートの色に基づいてグループが色分けされます。また、レコードのうち、マスターレコードはtrueと表示されます。各グループ内のマスターレコードは、2つの類似するレコードを音声アルゴリズムとサバイバーシップルールに従ってマージした結果です。マスターレコードは、入力データ内に存在しない新しいレコードです。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。