
セマンティックタイプを発見
データを検出すると各セマンティックタイプに一致する値の数が計算されます。結果が40%を超える場合は、カラムにセマンティックタイプを割り当てます。
40%を超える結果を取得するセマンティックタイプがない場合は、データの検出によってデータ型 (英語のみ)が割り当てられます。
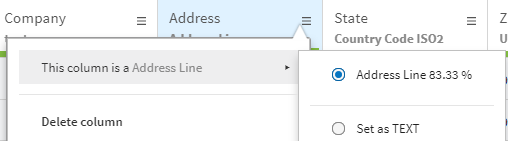
割合の計算方法
この割合は2つの割合の合計です。
- 一方はセマンティックタイプに一致する値の数を表すもので、100%まで割り当てられます。
値が意味型に一致するかどうかを判断するため、データの検出は次のセマンティックタイプに依存します。
- [Dictionary] (ディクショナリー): 値がディクショナリーの値と一致するかどうかを判断します。句読点、大文字と小文字、スペース、アクセントは無視されます。
- [Regular expression] (正規表現): 値が正規表現と一致するかどうかを判断します。
- [Compound] (複合): 値が少なくとも1つの子で検出されているかどうかを判断します。複合型は子と呼ばれる既存のセマンティックタイプのグループのことです。
答えが正であれば値は有効と見なされます。
- もう一方の割合はカラム名とセマンティックタイプ名との類似性を表すもので、10%まで割り当てられます。 名前を比較する場合:最大の割合は100%です。値がすべてセマンティックタイプと一致し、カラム名がセマンティックタイプ名と同一であれば、結果は100%のままとなります。
- レーベンアルゴリズムが使用されます。文字列を別の文字列に変換するために必要な編集(挿入、削除、置換のいずれか)の最小回数を計算します。
- 大文字と小文字の区別とアクセントは無視されます。
- 文字列にスペースが含まれている場合は語順が無視されます。たとえばUS PhoneとPhone USは同じものと見なされます。
クオリティバーの表示
クオリティバーは、割り当てられたセマンティックタイプに応じて無効値、空白値、有効値の数を示します。表示する場合は、セマンティックタイプの設定で[Use for validation] (検証で使用)を有効にします。
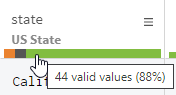 有効値の割合がデータ検出値よりも少ない場合がありますが、これは次のような場合に発生します。
有効値の割合がデータ検出値よりも少ない場合がありますが、これは次のような場合に発生します。
- 検証ルールがセマンティックタイプよりも厳しい。この場合、値はセマンティックタイプの値と一致しますが、検証ルールでは大文字と小文字や句読点などの値が一致しません。
- カラム名とセマンティックタイプ名が類似していれば、セマンティックタイプの結果が100%に引き上げられます。この場合、クオリティバーは有効値の90%~100%を示します。
データ型の検出
セマンティックタイプの代わりにデータ型を割り当てることができます。40%を超える結果を取得するセマンティックタイプがない場合は、データの検出によってデータ型が自動的に割り当てられます。
どのタイプが値であるかを判断できるよう、データの検出は次の順序に従います。
- その値は空白か?
- その値はBoolean型の値か? trueとfalseはBoolean型の値と見なされる唯一の値です。
- その値は整数型か?
- その値は10進数型か?
- その値は日付型か?
- 上記のいずれかの型でもない値はテキスト値と見なされます。
検証は増分的に行われるため、値のタイプは1つのみです。たとえば、5という値は整数型です。テキスト型の値とは見なされません。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。