
ConsumerRecordからAvroデータを読み取り
このタスクについて
読み取りジョブを設定するために使われます。
手順
-
読み取りジョブでtKafkaInputコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、次のパラメーターを指定します。
-
[Output type] (出力タイプ)ドロップダウンリストで、ConsumerRecordを選択します。
ConsumerRecordを使用する場合、AvroレコードはStudio Talendで次のようにオブジェクトとして分類されます。
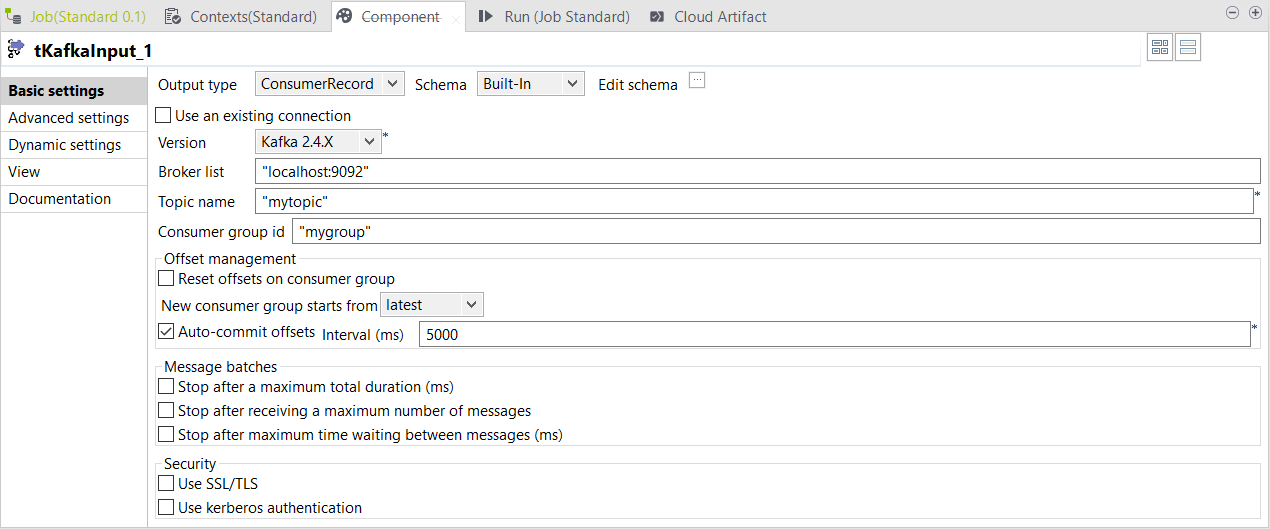
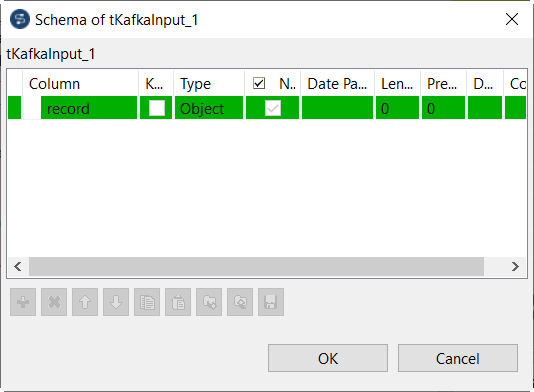
-
[Output type] (出力タイプ)ドロップダウンリストで、ConsumerRecordを選択します。
-
tJavaRowコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、次のパラメーターを指定します。
-
[+]ボタンをクリックしてカラムを追加し、そのカラムに名前を付けます。例:
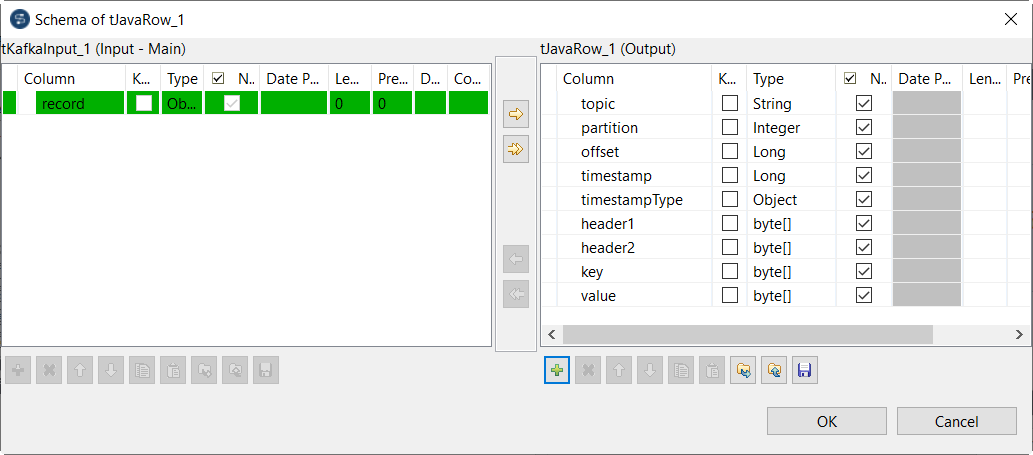
-
[+]ボタンをクリックしてカラムを追加し、そのカラムに名前を付けます。例:
-
tLogRowコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、次のパラメーターを指定します。
- [Mode] (モード)エリアで、[Table (print values in cells of a table)] (テーブル(テーブルのセルの出力値))を選択して結果を読みやすくします。
タスクの結果
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。