
標準ジョブを使ってKafkaに対してAvroデータを読み取りおよび書き込み
このシナリオでは、デシリアライザーでスキーマレジストリーを使用する方法と、標準ジョブでKafkaコンポーネントからConsumerRecordとProducerRecordを使ってAvroデータを処理する方法について説明します。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
このシナリオでは、まずConsumerRecordを使ってAvroデータを読み取る標準ジョブ(以下「読み取りジョブ」)を作成します。
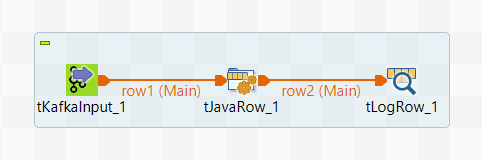
次に、ProducerRecordを使ってAvroデータを書き込む別の標準ジョブ(以下「書き込みジョブ」)を作成します。
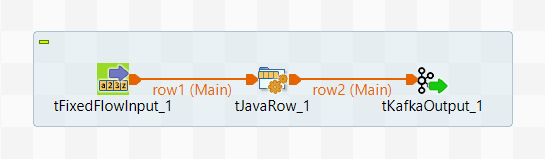
このシナリオは、ビッグデータ関連のTalend製品およびTalend Data Fabricにのみ適用されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。