
ほぼリアルタイムでTwitterの流れを分析する
このシナリオはTalend Real-Time Big Data PlatformとTalend Data Fabricにのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご参照ください。
このシナリオでは、Spark Streamingジョブを作成して、各15秒間隔の最後に、Twitterユーザーが前回の20秒間に自分のツイートでパリに言及した際に最もよく使用しているハッシュタグを分析します。
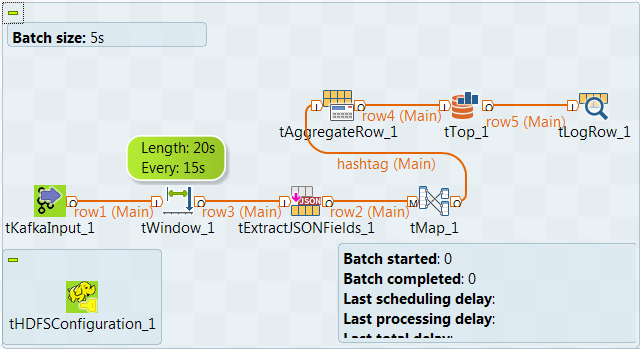
たとえば、オープンソースのサードパーティプログラムを使用して、特定のKafkaトピックtwitter_liveでTwitterストリームを送受信し、このトピックのツイートを使用するためにこのシナリオで設計したジョブを使用します。
ハッシュタグ付きのTwitter生データの行は、https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtagsで示されている例のように読み取られます。
このシナリオを複製する前に、Kafkaシステムが稼動していること、また、使用するKafkaトピックにアクセスするための適切な権限とアクセス権があることを確認します。また、TwitterストリームをほぼリアルタイムでKafkaに転送するには、Twitterストリーミングプログラムが必要です。 Talend は、この種のプログラムを提供していませんが、この目的のために作成されたいくつかの無料のプログラムがGithubなどの一部のオンラインコミュニティから入手できます。
tHDFSConfigurationはこのシナリオで、ジョブに依存するjarファイルの転送先となるHDFSシステムに接続するために、Sparkによって使用されます。
-
Yarnモード(YarnクライアントまたはYarnクラスター):
-
Google Dataprocを使用している場合、[Spark configuration] (Spark設定)タブの[Google Storage staging bucket] (Google Storageステージングバケット)フィールドにバケットを指定します。
-
HDInsightを使用している場合、[Spark configuration] (Spark設定)タブの[Windows Azure Storage configuration] (Windows Azure Storage設定)エリアでジョブのデプロイメントに使用するブロブを指定します。
- Altusを使用する場合は、[Spark configuration] (Spark設定)タブでジョブのデプロイにS3バケットまたはAzure Data Lake Storageを指定します。
-
オンプレミスのディストリビューションを使用する場合は、クラスターで使われているファイルシステムに対応する設定コンポーネントを使用します。一般的に、このシステムはHDFSになるため、tHDFSConfigurationを使用します。
-
-
[Standalone mode] (スタンドアロンモード): クラスターで使われているファイルシステム(tHDFSConfiguration Apache Spark BatchやtS3Configuration Apache Spark Batchなど)に対応する設定コンポーネントを使用します。
ジョブ内に設定コンポーネントがない状態でDatabricksを使用している場合、ビジネスデータはDBFS (Databricks Filesystem)に直接書き込まれます。
このシナリオを複製するには、次の手順に従います。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。