
RAWツイートデータからハッシュタグフィールドを抽出
手順
-
tExtractJSONFieldsをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
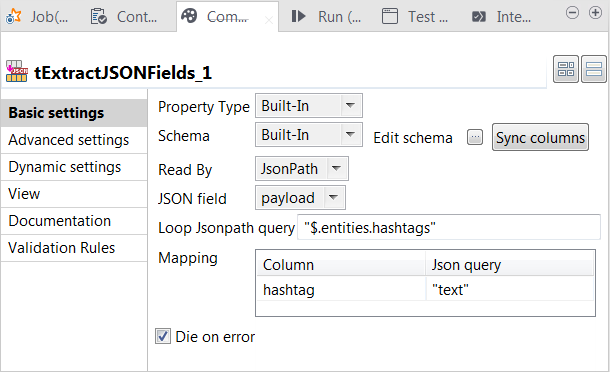 https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtagsからわかるように、RAWツイートデータはJSON形式を使います。
https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtagsからわかるように、RAWツイートデータはJSON形式を使います。 -
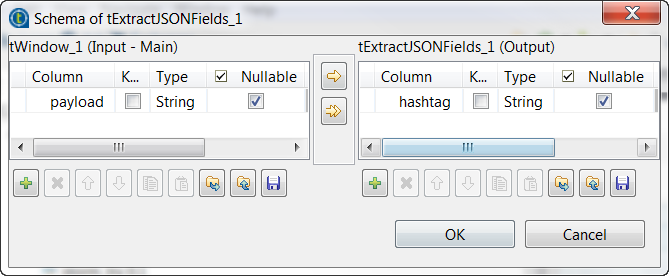
[Edit schema] (スキーマを編集)の横の[...]ボタンをクリックし、スキーマエディターを開きます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。