
ジョブを設定してHadoopクラスター上で実行
このセクションでは、ジョブを設定して、Hadoopクラスター上で直接実行する方法について説明します。
手順
-
次の[Advanced properties] (詳細プロパティ)を追加します。
 この値はHadoopのディストリビューションとバージョン固有のものです。このチュートリアルでは、2.4.0.0-169であるHortonworks 2.4 V3を使います。Hortonworks 2.4 V3を使わない場合は、このパラメーターのエントリーが異なります。情報メモ注: クラスター上でコードを実行する時に、2つのシステム間の自由なアクセスがあることを確認することが重要です。この例では、HortonworksクラスターがTalend Studioのインスタンスと通信できることを確認します。クラスター上で実行されていても、SparkがTalendに同梱されているSparkドライバーを参照する必要があるため、必須です。さらに、Sparkジョブを本番環境にデプロイする場合は、Talendジョブサーバー(エッジノード)から実行されます。これとクラスターの間に自由な通信があることを確認する必要もあります。
この値はHadoopのディストリビューションとバージョン固有のものです。このチュートリアルでは、2.4.0.0-169であるHortonworks 2.4 V3を使います。Hortonworks 2.4 V3を使わない場合は、このパラメーターのエントリーが異なります。情報メモ注: クラスター上でコードを実行する時に、2つのシステム間の自由なアクセスがあることを確認することが重要です。この例では、HortonworksクラスターがTalend Studioのインスタンスと通信できることを確認します。クラスター上で実行されていても、SparkがTalendに同梱されているSparkドライバーを参照する必要があるため、必須です。さらに、Sparkジョブを本番環境にデプロイする場合は、Talendジョブサーバー(エッジノード)から実行されます。これとクラスターの間に自由な通信があることを確認する必要もあります。各サービスに必要なポートの詳細は、Spark Securityドキュメンテーションをご覧ください。
-
[Advanced settings] (詳細設定)タブを選択し、Hadoopのバージョンを示す新しいJVM引数を追加します。
前のステップで、値として追加した文字列です。

-
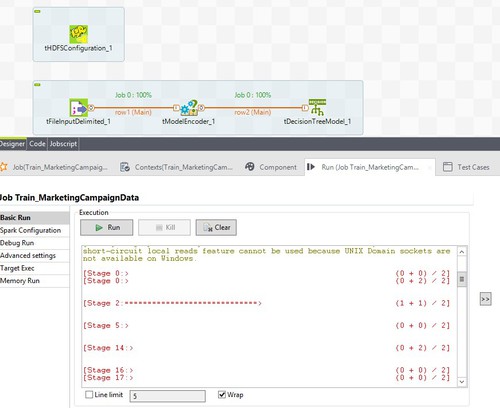
[Basic Run] (基本実行)タブを選択した後に、[Run] (実行)をクリックします。
完了したら、成功を示すメッセージが表示されます。
-
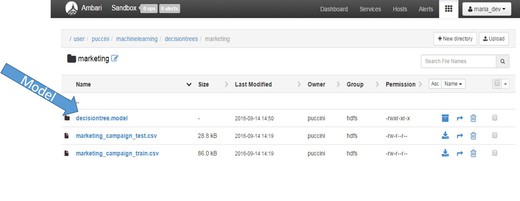
HDFSディレクトリー(この例ではAmbari)に移動し、モデルが作成済みでありHDFSに永続化されていることを検証します。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。