
トレーニングデータを暗号化
手順
-
[Main] (メイン)行を使って、tFileInputDelimitedをtModelEncoderに接続します。
-
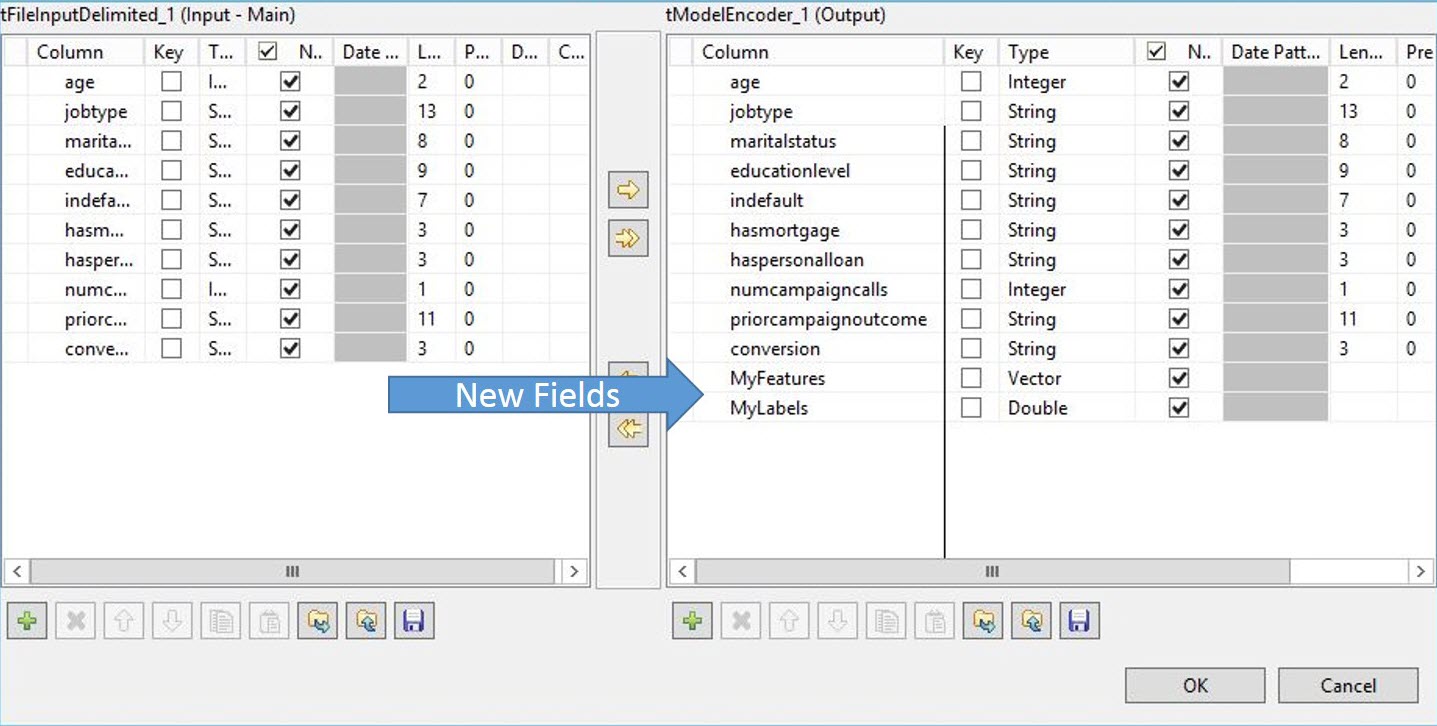
VectorというタイプのMyFeaturesとDoubleというタイプのMyLabelsという2つの新しいカラムを出力に追加します。
-
[Component] (コンポーネント)ビューの[Basic settings] (基本設定)タブで
 をクリックし、新しい変換を追加します。
をクリックし、新しい変換を追加します。
-
次のコードを[Parameters] (パラメーター)フィールドに追加します。
featuresCol=MyFeatures;labelCol=MyLabels;formula=conversion ~ age + jobtype + maritalstatus + educationlevel + indefault + hasmortgage + haspersonalloan + numcampaigncalls + priorcampaignoutcome
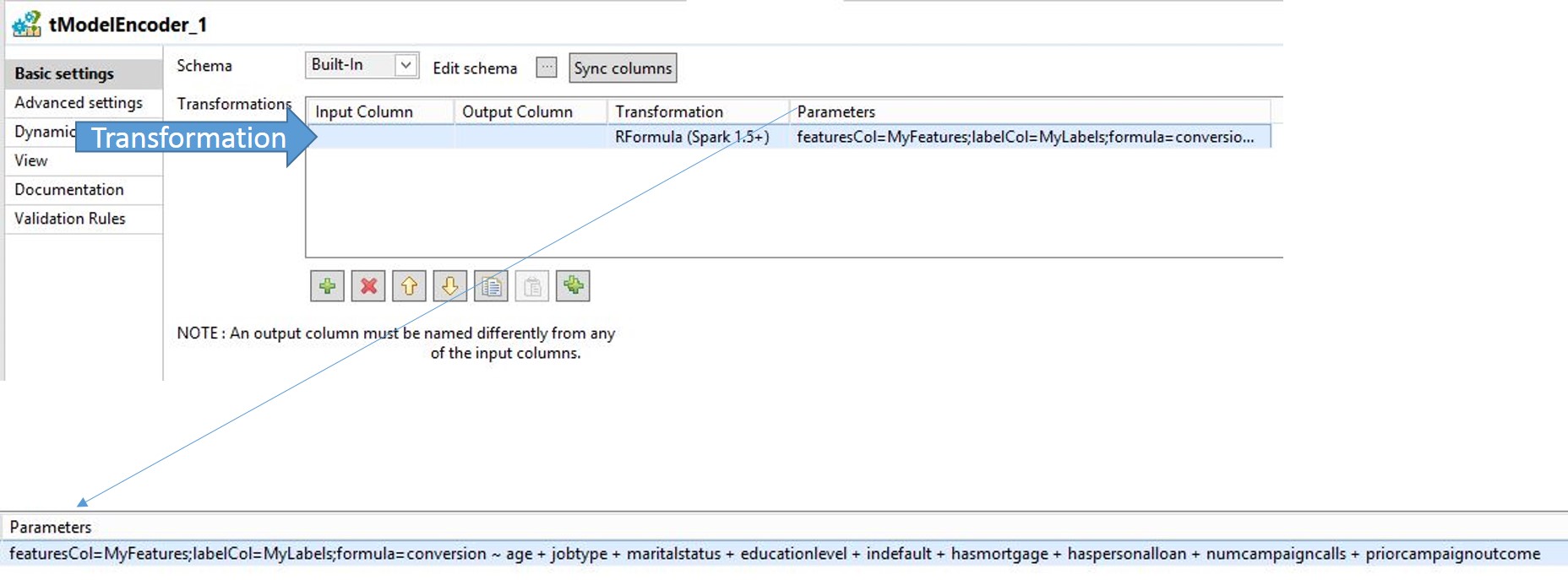
MyFeaturesとMyLabelsという、スキーマに追加される2つのカラムがここで参照されています。この式は、統計計算や高度なグラフィックスに使われるプログラミング言語Rで使用される標準構文です。詳細は、The R Projectをご覧ください。
データのサンプリングには、機能が9つ、ターゲットが1つありました。上のRの式の場合、予測したいターゲットはconversion (変換)で、チルダの左にあります。チルダの右にあるカラムはすべて特徴です。残る2つのコンポーネントであるfeaturesColとlabelColは、タプルとフィーチャーラベルのプレースホルダーです。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。