
データサイエンスの基礎を理解
このセクションでは、機械学習で使用される重要なコンセプトをいくつか紹介します。
以下のコンセプトは機械学習に重要で、データサイエンティストが分類モデルの評価に使う標準ツールの一部です。
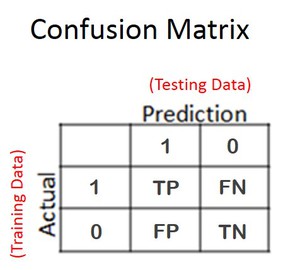
- 混同行列: 結果が知られているテストデータに対して、分類モデルパフォーマンスの視覚的な観察を簡単にできる専用テーブル(監視学習)
- 真陰性 (TN): 予測が現在の結果と同等(正確な拒否)
- 真陽性 (TP): 予測が現在の結果と同等(正確なヒット)
- 偽陰性 (FN): 予測が失敗 (誤った拒否) (タイプIIエラー)
- 偽陽性 (FP): 予測が失敗 (誤ったヒット) (タイプIエラー)
- 精度: 全体で、分類子が正しい頻度。A = (TP+TN)/Total
- 真陽性率(感度): TP/(TP+FN)
- 真陰性(特異度): TN/(FP+TN)
以下は、どうやってレイアウトされるかを示す一般化された混同行列です。
これが一般的な混同行列の簡単で具体的な使用サンプルです。猫と犬の一連の画像を分析して、どれが猫の画像で、どれがそうではない(この場合は犬)かを識別するようモデルをトレーニングしたことを前提とします。モデルが完璧である場合は、100%の精度が予測されます。モデルの結果が0%の精度である可能性もあります。しかし、最も可能性の高い結果は、混同行列が役立てる中間にあります。
以下は、仮定の結果です。
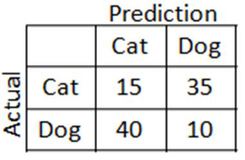
この仮説モデルは、15枚猫の画像を正確に予測し(TP)、10枚の犬(または猫ではない)の画像も正確に予測しました(TN)。ただし、このモデルは40匹の犬を猫と誤認し(FN)、35匹の猫を犬と誤認しました(FP)。
- この分類子の精度: (15+10) / (15+35+40+10) = .25
- この分類子の感度: 15/(15+35) = .3
- この分類子の特異度: 10/(40+10) = .2
結論としては、このモデルは全体で25%の確率で正しいということになります(精度)。猫の画像である場合に、このモデルは猫を30%の確率で正確に予測します(感度)。猫の画像ではない場合、このモデルは猫ではないことを20%の確率で正確に予測します(特異度)。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。