
Big Data: 新機能
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark Universalのサポート | [Local] (ローカル)モードと[Yarn cluster] (Yarnクラスター)モードのどちらかで、Spark 2.4.xまたはSpark 3.0.xでSpark Universalを使って、Sparkジョブを実行できるようになりました。 Spark Universalとは、[Yarn cluster] (Yarnクラスター)でクラスターへの接続の確立に必要な情報が含まれるHadoop設定JARファイルのみを使って、特定のSparkバージョンの利用できるすべてのビッグデータディストリビューションとTalend Studioの間の互換性があるようにするメカニズムです。 Spark Universalによって、さまざまなSparkモード、ディストリビューション、環境のいずれかの間のスイッチが有効化されるため、俊敏性が向上します。 ジョブの[Spark configuration] (Spark設定)ビューと[Repository] (リポジトリー)ツリービューからの[Hadoop Cluster Connection] (Hadoopクラスター接続)のどちらかでSpark Universal接続を設定できます:
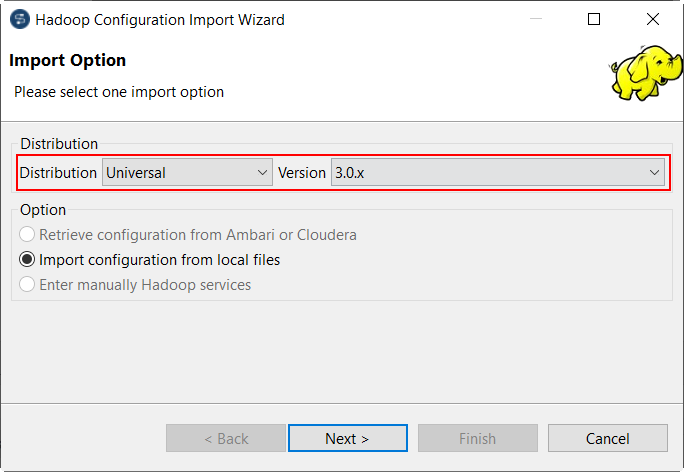
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.1.xでKubernetesのサポート | [Kubernetes]モードで、Spark 3.1.xでSpark Universalを使って、Sparkジョブを実行できるようになりました。 KubernetesとのSpark Universal接続は、ジョブの[Spark configuration] (Spark設定)ビューと[Repository] (リポジトリー)ツリービューからの[Hadoop Cluster Connection] (Hadoopクラスター接続)のいずれかで設定できます:
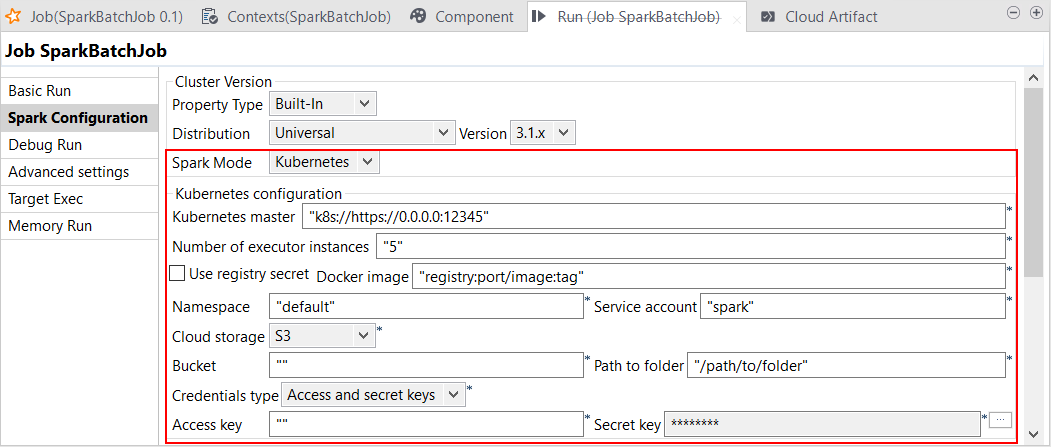
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Batchコンポーネントでのダイナミックスキーマのサポート | Sparkジョブで、以下のコンポーネントを使って、ダイナミックスキーマを使えるようになりました:
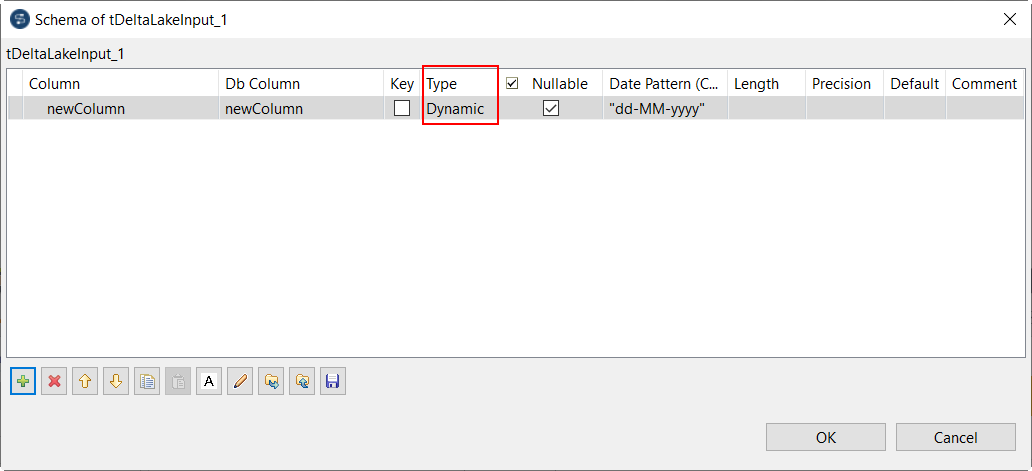
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。