
コンポーネントを設定
手順
-
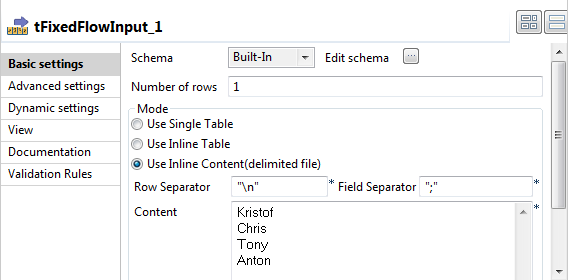
tFixedFlowInputをダブルクリックして、[Basic settings] (基本設定)ビューを開きます。
-
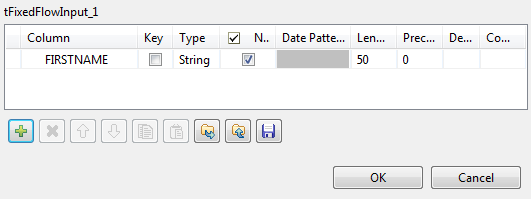
[Schema] (スキーマ)フィールドの横にある[Edit schema] (スキーマを編集)ボタンをクリックして[Schema] (スキーマ)ダイアログボックスを開き、カラムを1つ追加してFIRSTNAMEという名前を付けます。続いて、[OK]をクリックして変更を確定し、ダイアログボックスを閉じます。
-
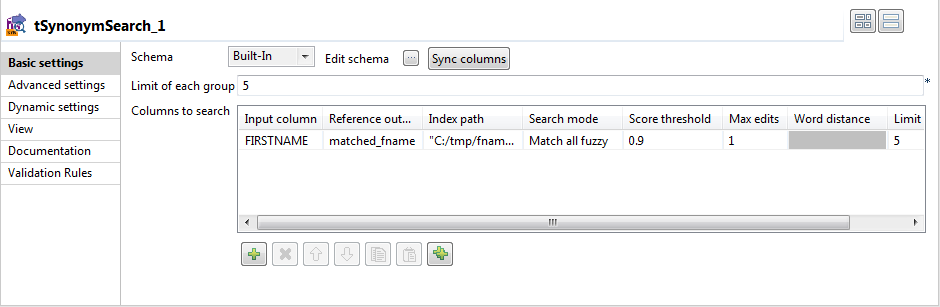
tSynonymSearchをダブルクリックして[Basic settings] (基本設定)ビューを開きます。
-
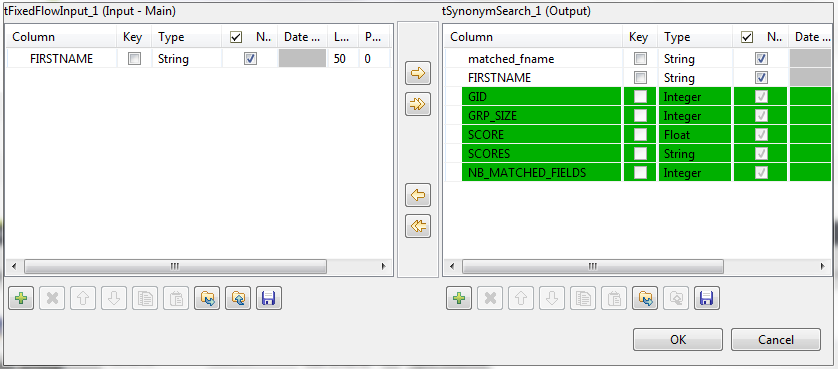
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックして[Schema] (スキーマ)ダイアログボックスを開き、出力スキーマに1つのカラムを追加します: matched_fname。
このカラムには、出力フローで一致した参照エントリーが保持されます。続いて、[OK]をクリックして設定を確定し、プロンプトが表示されたら変更の伝播を承諾します。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。