
テスト顧客データを生成して処理
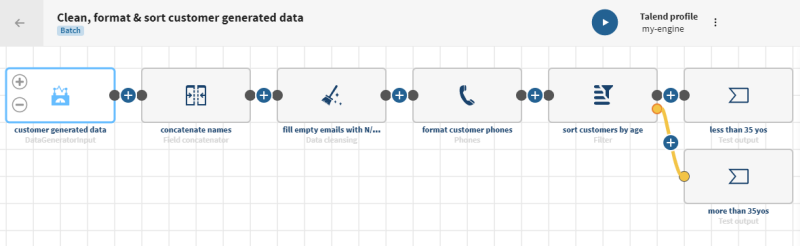
手順
-
プロパティを入力して、目的のテスト顧客データを生成します。この例では、単純なLDAPプロトコルを使用しています。
- テストレコードを100件生成したいので、[Rows] (行)フィールドに100を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにfirstnameを入力し、[Type] (タイプ)リストで[First Name] (ファーストネーム)を選択して、空のフィールドを含まないランダムなファーストネームを生成したいので、[Blank %] (空白%)フィールド内に0を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにlastnameを入力し、[Type] (タイプ)リストで[Last Name] (ラストネーム)を選択して、空のフィールドを含まないランダムなラストネームを生成したいので、[Blank %] (空白%)フィールド内に0を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにageを入力し、[Type] (タイプ)リストで[Age] (年齢)を選択して、空のフィールドを含まない18歳から99歳の年齢を生成したいので、[Min] (最小)フィールドに18、[Max] (最大)フィールドに99、[Blank %] (空白%)フィールドに0を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにhair_colorを入力し、[Type] (タイプ)リストで[Random within list] (リスト内のランダム)を選択して、[Blank %] (空白%)フィールド内に0を入力します。作成したいランダムリストにエレメント(ここでは、異なる髪色の値と重み)を追加します。
- 40%の茶髪、20%の金髪、40%の赤髪を含む髪色フィールドを生成したいので、1番目[Element] (エレメント)フィールドにbrown、[Weight] (重み)フィールドに0.4を入力します。2番目の[Element] (エレメント)フィールドにblond、[Weight] (重み)フィールドに0.2を入力します。3番目の[Element] (エレメント)フィールドにred、[Weight] (重み)フィールドに0.4を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにemailを入力し、[Type] (タイプ)リストで[Email] (メールアドレス)を選択して、20%の空の値を含むランダムなメールアドレスを生成したいので、[Blank %] (空白%)フィールド内に20を入力します。
- [Add] (追加)フィールドをクリックし、エレメントの[Name] (名前)フィールドにphoneを入力し、[Type] (タイプ)リストで[Phone number (ext)] (電話番号(内線))を選択して、空の値を含まないランダムな電話番号を生成したいので、[Blank %] (空白%)フィールド内に0を入力します。
- [Validate] (検証)をクリックしてデータセットを保存します。データセット詳細ビューに、定義した条件に対応する生成されたデータが表示されます。
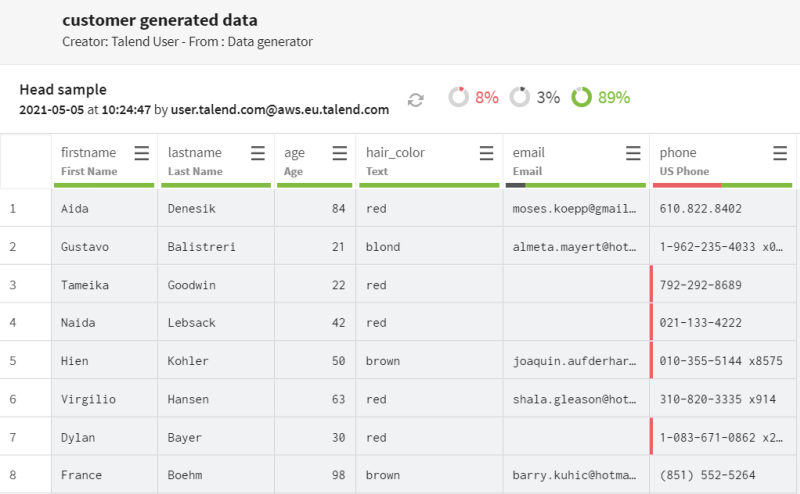
-
 をクリックし、パイプラインにField concatenatorプロセッサーを追加します。意味のある名前(たとえばconcatenate names)を付け、[Concatenate with value/another field] (値/別のフィールドと連結)関数を使って、firstnameフィールドとlastnameフィールドを連結します。
をクリックし、パイプラインにField concatenatorプロセッサーを追加します。意味のある名前(たとえばconcatenate names)を付け、[Concatenate with value/another field] (値/別のフィールドと連結)関数を使って、firstnameフィールドとlastnameフィールドを連結します。
-
[Save] (保存)をクリックして設定を保存します。
これで、ファーストネームとラストネームがすべて、スペースを区切りとして結合されました。
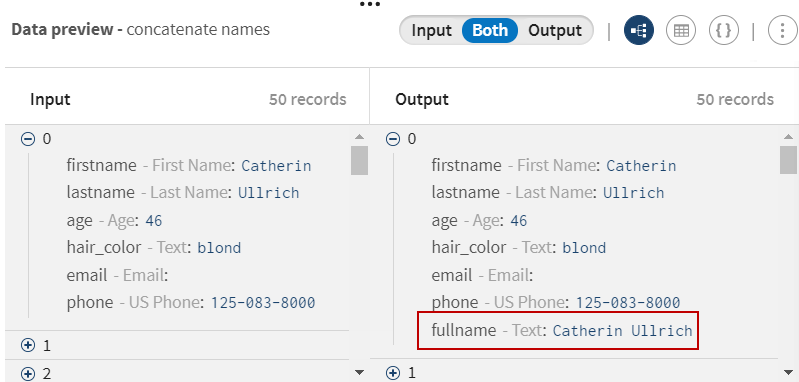
-
をクリックして、Data cleansingプロセッサーをパイプラインに追加します。意味のある名前(たとえば、fill empty emails with N/A)を付け、[Fill empty cells with text] (空のセルにテキストを入力)関数を使って、[email] (メールアドレス)の空の値にN/Aテキストを入力します。
-
[Save] (保存)をクリックして設定を保存します。
メールアドレスフィールド内の空の値はすべてN/Aで置換されます。
-
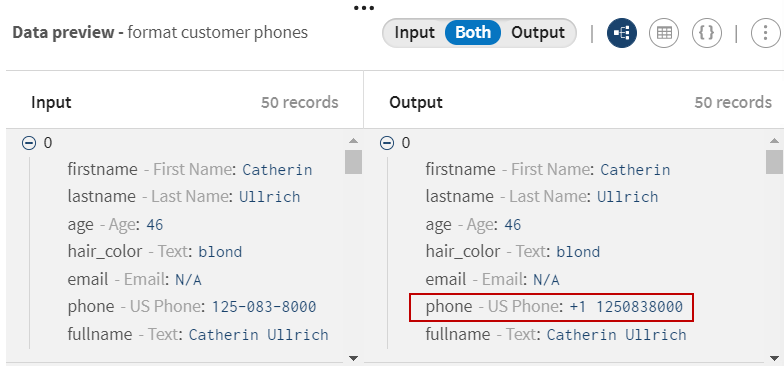
をクリックし、Phonesプロセッサーをパイプラインに追加します。意味のある名前(たとえば、format customer phones)を付け、[Format phone number] (電話番号をフォーマット)関数を使って、正しいアメリカ標準構文を使用して、生成された電話番号フィールドをフォーマットします。
-
[Save] (保存)をクリックして設定を保存します。
電話番号の値はすべてフォーマットされるようになりました。
-
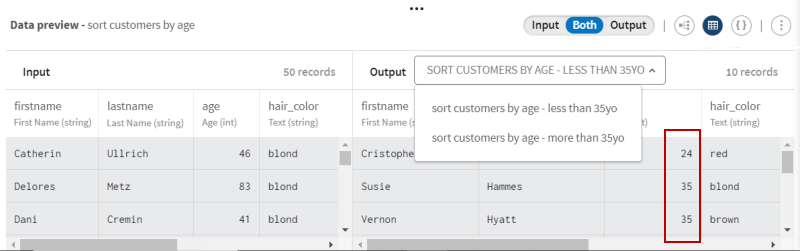
をクリックし、パイプラインにFilterプロセッサーを追加します。意味のある名前(たとえば、sort customers by age)を付け、35値で[ <= Operator] (<= 演算子)を使って、年齢(35歳以下か以上)に基づいて顧客を分割します。
-
[Save] (保存)をクリックして設定を保存します。
このプレビューでは、定義した条件(35歳以下)と一致するレコードが10件あります。
-
Filterプロセッサーにある
 ボタンをクリックし、リジェクトデータを保存するデータセットを選択します。
必要であれば名前を変更します。
ボタンをクリックし、リジェクトデータを保存するデータセットを選択します。
必要であれば名前を変更します。
タスクの結果
パイプラインは実行中となり、生成された100件のテストフィールドが処理中で、定義したテストデータセットに出力フローが送信されます。ログで、データが35歳以下の顧客と35歳以上の顧客に分割されていることが表示されます。

このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。