
Générer des données client·es de test et les traiter
Procédure
-
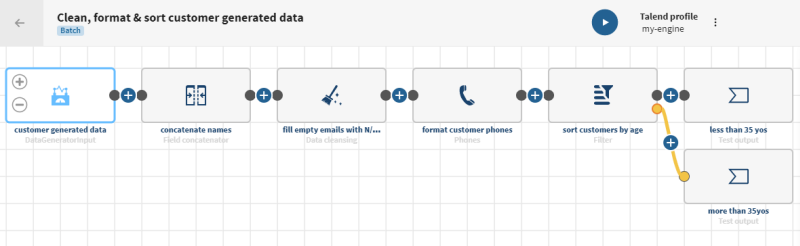
Renseignez les propriétés pour générer les données client·es de test de votre choix. Dans cet exemple:
- Dans le champ Rows (Lignes), saisissez 100 pour générer 100 enregistrements de test.
- Cliquez sur Add (Ajouter) , saisissez firstname dans le champ Name de l'élément, sélectionnez First Name dans la liste Type et saisissez 0 dans le champ Blank % (% vide) pour générer des prénoms aléatoires sans champ vide.
- Cliquez sur Add (Ajouter) , saisissez lastname dans le champ Name de l'élément, sélectionnez Last Name dans la liste Type et saisissez 0 dans le champ Blank % (% vide) pour générer des noms de famille aléatoires sans champ vide.
- Cliquez sur Add (Ajouter) , saisissez age dans le champ Name de l'élément, sélectionnez Age dans la liste Type. Saisissez 18 dans le champ Min et 99 dans le champ Max et saisissez 0 dans le champ Blank % (% vide), car vous souhaitez générer des âges compris entre 18 et 99, sans champ vide.
- Cliquez sur Add (Ajouter), saisissez hair_color dans le champ Name de l'élément, sélectionnez Random within list (Aléatoire au sein de la liste) dans la liste Type et saisissez 0 dans le champ Blank % (% vide). Ajoutez les éléments à la liste aléatoire que vous souhaitez créer, ici différentes valeurs relatives aux couleurs de cheveux et au poids.
- Saisissez brown dans le premier champ Element et 0.4 dans le champ Weight (Poids), saisissez blond dans le deuxième champ Element et 0.2 dans le champ Weight (Poids) et saisissez red dans le troisième champ Element et 0.4 dans le champ Weight (Poids), car vous souhaitez générer des champs relatifs aux couleurs de cheveux contenant 40 % de cheveux bruns (brown), 20 % de cheveux blonds et 40 % de cheveux roux (red).
- Cliquez sur Add (Ajouter) , saisissez email dans le champ Name de l'élément, sélectionnez Email dans la liste Type et saisissez 20 dans le champ Blank % (% vide) pour générer des adresses e-mail aléatoires avec 20 % de champs vides.
- Cliquez sur Add (Ajouter) , saisissez phone dans le champ Name de l'élément, sélectionnez Phone number (ext) dans la liste Type et saisissez 0 dans le champ Blank % (% vide) pour générer des numéros de téléphone aléatoires sans champ vide.
- Cliquez sur Validate (Valider) pour sauvegarder votre jeu de données. Dans la vue détaillée du jeu de données, vous pouvez voir les données générées correspondant aux critères définis.
-
Cliquez sur
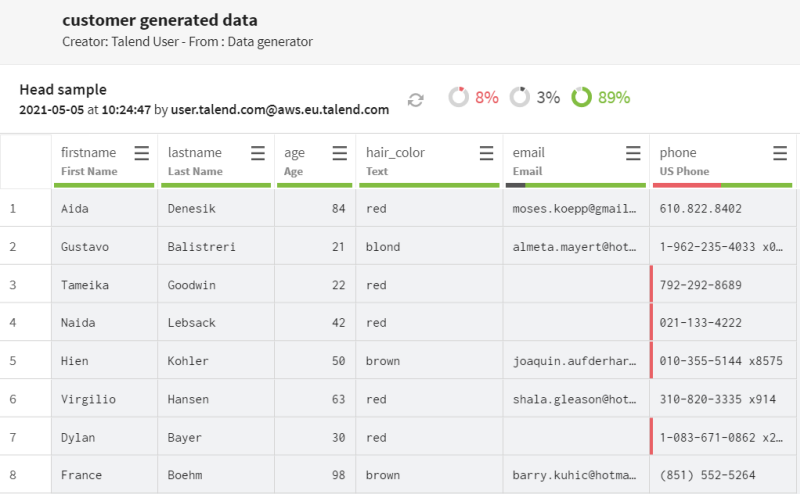
 et ajoutez un processeur Field concatenator au pipeline. Donnez-lui un nom significatif, concatenate names par exemple et utilisez la fonction Concatenate with value/another field (Concaténer à une valeur/un autre champ) afin de concaténer les champs firstname et lastname.
et ajoutez un processeur Field concatenator au pipeline. Donnez-lui un nom significatif, concatenate names par exemple et utilisez la fonction Concatenate with value/another field (Concaténer à une valeur/un autre champ) afin de concaténer les champs firstname et lastname.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Tous les prénoms et les noms de famille sont à présent combinés, avec un espace comme séparateur.
-
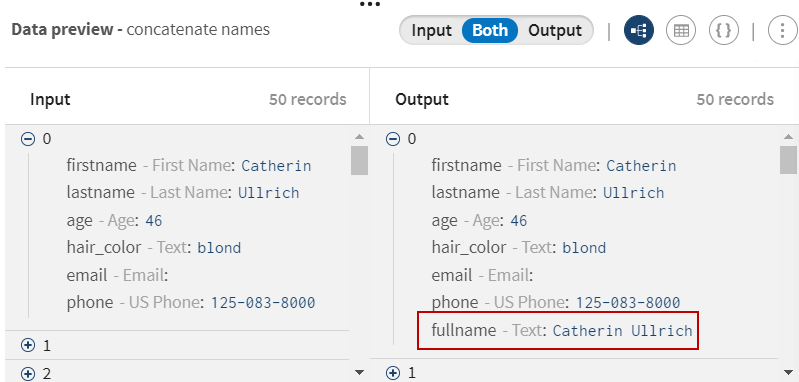
Cliquez sur et ajoutez un processeur Data cleansing au pipeline. Donnez-lui un nom significatif, fill empty emails with N/A par exemple et utilisez la fonction Fill empty cells with text pour remplacer les valeurs vides d'email par le texte N/A.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Toutes les valeurs vides dans les champs d'e-mail sont remplacées par N/A.
-
Cliquez sur et ajoutez un processeur Phones au pipeline. Donnez-lui un nom significatif, format customer phones par exemple et utilisez la fonction Format phone number pour formater les champs générés de numéros de téléphone à l'aide de la syntaxe américaine standard.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
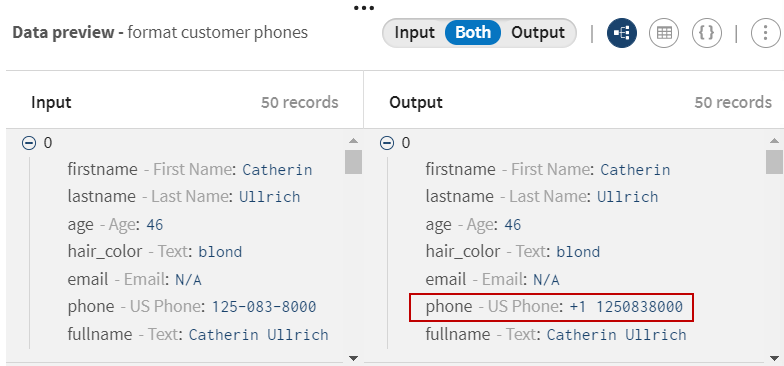
Toutes les valeurs de numéros de téléphone sont à présent formatées.
-
Cliquez sur et ajoutez un processeur Filter au pipeline. Donnez-lui un nom significatif, sort customers by age par exemple et utilisez <= comme Operator (Opérateur) avec la valeur 35 pour scinder les client·es par âge (inférieur ou supérieur à 35 ans).
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
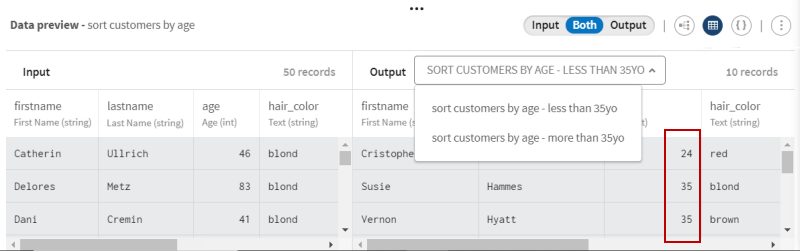
Dans cet aperçu, 10 enregistrements correspondent au critère (moins de 35 ans) défini.
-
Cliquez sur le bouton
 à côté du processeur Filter et sélectionnez le jeu de données qui contiendra vos données rejetées.
Renommez-le si nécessaire.
à côté du processeur Filter et sélectionnez le jeu de données qui contiendra vos données rejetées.
Renommez-le si nécessaire.
Résultats
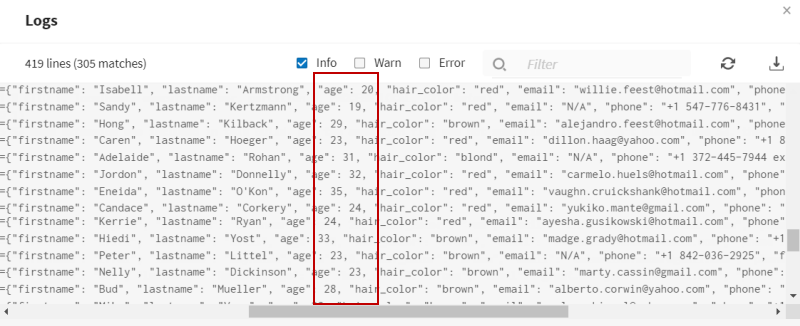
Votre pipeline est en cours d'exécution. Les 100 champs de test générés sont traités et les flux de données sont envoyés aux jeux de données de test définis. Vous pouvez voir dans les logs que les données sont divisées entre les client·es ayant moins de 35 ans et les client·es ayant plus de 35 ans.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !