
データをKafkaトピックに送信
このシナリオは、パイプラインでコネクターを簡単にセットアップして使用できるようにすることを目的としています。お使いの環境とユースケースに適応させてください。
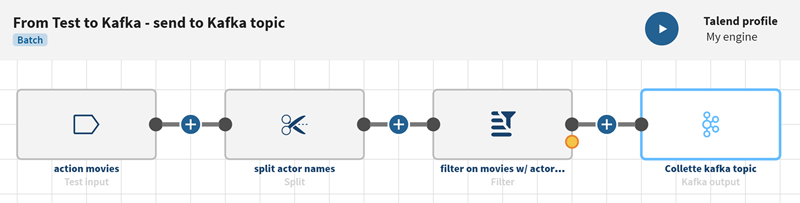
始める前に
- このシナリオを再現する場合は、test-file-to-kafka.zipファイルをダウンロードして抽出します。
手順
-
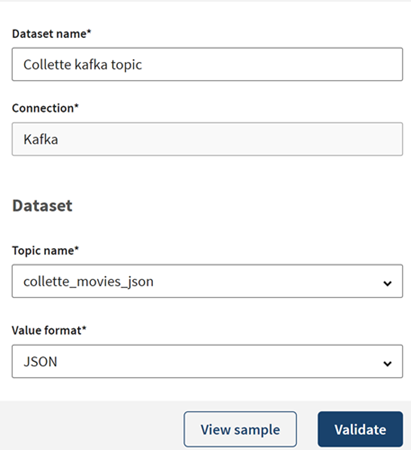
[Add a new dataset] (新しいデータセットを追加)パネルで、データセットに名前を付けます。この例では、collette_movies_jsonトピックを使って映画に関するデータを公開します。
例
-
 をクリックしてSplitプロセッサーをパイプラインに追加して俳優のファーストネームとラストネームの両方が含まれているレコードを分割できるようにします。設定パネルが開きます。
をクリックしてSplitプロセッサーをパイプラインに追加して俳優のファーストネームとラストネームの両方が含まれているレコードを分割できるようにします。設定パネルが開きます。
-
オプションとして、プロセッサーのプレビューを表示し、分割操作後のデータを確認します。

-
をクリックして、パイプラインにFilterプロセッサーを追加します。設定パネルが開きます。
-
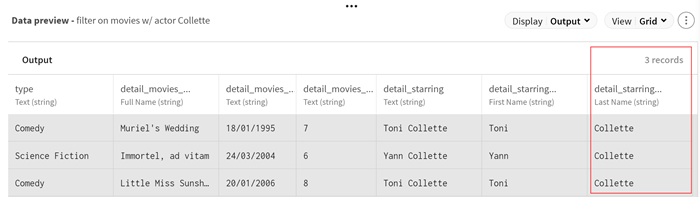
オプションとして、Filterプロセッサーのプレビューを表示し、フィルタリング操作後のデータサンプルを確認します。
例
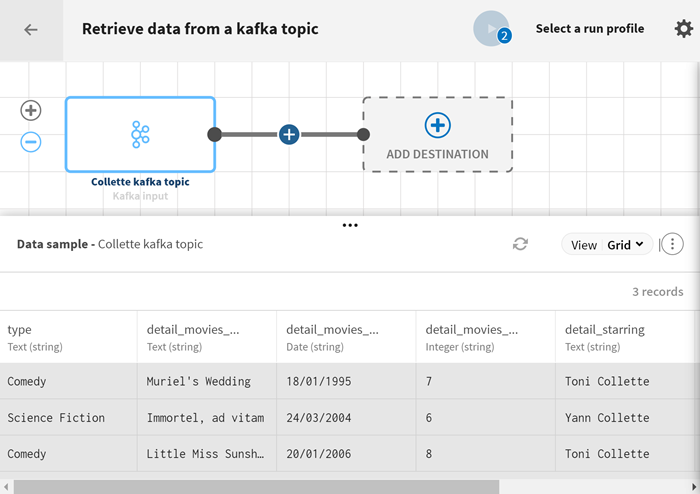
タスクの結果
パイプラインは実行中となり、テストファイルからの映画データが処理され、定義したcollette_movies_json トピックに出力フローが送信されます。
次のタスク
イベントが公開された後は、別のパイプラインでトピックのコンテンツを消費してソースとして使用できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。