
クラウドデータスウェアハウス(Snowflake)にデータを書き込む
始める前に
-
financial_transactions.avroファイルをダウンロードしてAmazon S3バケットにアップロード済みであること。
- クラウドストレージ(S3)にデータを書き込むの説明に従ってパイプラインを再現および複製済みであること。作業は、複製されたそのパイプラインで行われます。
- Talend Management ConsoleからMoteur distant Gen2とその実行プロファイルを作成済みであること。
ユーザーがアプリをすばやく開始できるよう、Talend Management ConsoleにはMoteur Cloud pour le designとそれに対応する実行プロファイルがデフォルトで組み込まれていますが、データの高度な処理のためにはセキュアなMoteur distant Gen2をインストールすることをお勧めします。
手順
-
[View sample] (サンプルを表示)をクリックして、データが有効かつプレビュー可能であることを確認します。
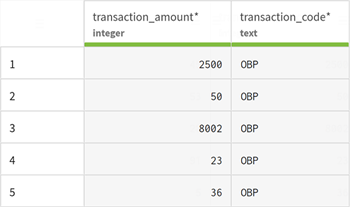
-
[Validate] (検証)をクリックしてデータセットを保存します。[Datasets] (データセット)ページに新しいデータセットがリストに追加されます。これはパイプラインでデスティネーションデータセットとして使用できます。
入力スキーマがフラットでないため、デスティネーションの横にあるデータマッピングアイコンはこの時点では無効になっています。
-
 アイコンをクリックしてAggregateプロセッサーの後にField selectorプロセッサーを追加し、保持したいフィールドを選択してスキーマをフラットにします。設定パネルが開きます。
アイコンをクリックしてAggregateプロセッサーの後にField selectorプロセッサーを追加し、保持したいフィールドを選択してスキーマをフラットにします。設定パネルが開きます。
-
[Simple] (シンプル)選択モードで、
![[Edit] (編集)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-edit-window.png) をクリックして[Select fields] (フィールドを選択)ウィンドウを開きます:
をクリックして[Select fields] (フィールドを選択)ウィンドウを開きます:
- 保持してフラット化したいフィールドであるdescriptionとtotal_amountを選択します。
- [Edit] (編集)をクリックしてウィンドウを閉じます。
- [Save] (保存)をクリックすると、設定が保存され、フラット化されたフィールドがプレビューされます。
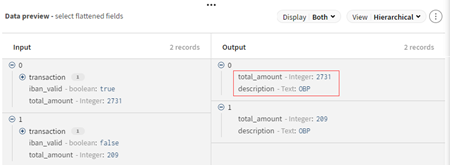
-
入力スキーマがフラットになったので、
![[Add a Mapper] (マッパーを追加)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-mapper.png) アイコンが有効になり、パイプラインにData mappingプロセッサーを追加できるようになります。設定パネルが開きます。
アイコンが有効になり、パイプラインにData mappingプロセッサーを追加できるようになります。設定パネルが開きます。
-
[Configuration] (設定)タブで[Open mapping] (マッピングを開く)をクリックし、Data mappingプロセッサーを開きます。
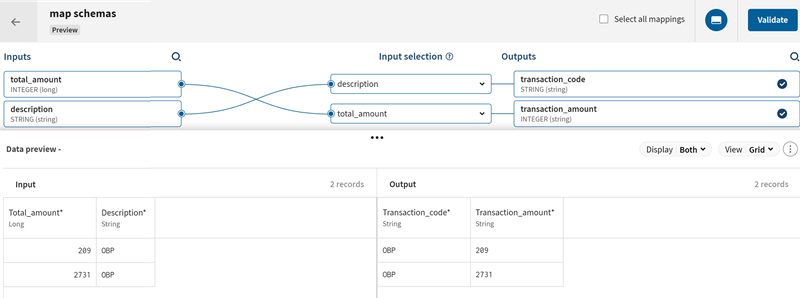
入力フィールドの一部は、その名前に基づいて自動的に出力フィールドとマッピングされます。そのようなフィールドをレビューし、スキーマの残りの部分のマッピングを開始します。
- total_amount入力フィールドをtransaction_amount出力フィールドにマッピングします。
- description入力フィールドをtransaction_code出力フィールドにマッピングします。
- [Validate] (検証)をクリックしてマッピングを確定します。
total_amount入力フィールドのコンテンツは、データベースで設定されている操作(挿入、アップデート、アップサート、削除)に従ってtransaction_amount出力フィールドのコンテンツに追加されます。
description入力フィールドのコンテンツは、transaction_code出力フィールドのコンテンツに追加されます。
マッピングの結果は[Data preview] (データ プレビュー)エリアでチェックできます。
-
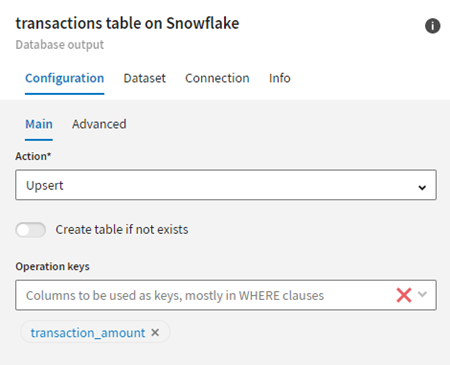
このパイプラインを実行する前に、Snowflakeデータセットの設定タブで[Upsert] (アップサート)を選択し、Snowflakeテーブルに新しいデータをアップデートして挿入します。transaction_amountフィールドを操作キーとして定義します。
タスクの結果
パイプラインが実行されると、アップデートされたデータがSnowflakeデータベーステーブルに表示されるようになります。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。