
コンテキスト変数を使って実行時に異なるデータセットを使用
このシナリオでは、実行時にソースと宛先として使用される両方のデータセットをオーバーライドするためにコンテキスト変数が追加されます。

始める前に
-
ソースデータを保存するシステムへの接続(ここではHTTPクライアント接続)が作成されていること。
接続の基本URLは、https://datausa.io/です。
-
ソースデータを保管するデータセットが追加済みであること。
ここでは、人口統計が含まれている米国の公共データが対象です。
HTTPクライアントデータセットのプロパティは次のとおりです。- HTTPメソッド: GET
- パス: /api/data
- クエリーパラメーター: 名前: drilldowns 値: Nation、名前: measures 値: Population
- レスポンスボディ形式: JSON
- レスポンスのサブ部分を抽出: .data
- 返されたコンテンツ: ボディ
- また、デスティネーション接続(ここではGoogle BigQuery接続とNation_statisticsという名前のBigQueryデータセット)が作成されていること。このBigQueryテーブルは実行時に作成され、年ごとの米国の統計が含まれます。
手順
-
 をクリックし、パイプラインにFilterプロセッサーを追加します。[Configuration] (設定)パネルが開きます。
をクリックし、パイプラインにFilterプロセッサーを追加します。[Configuration] (設定)パネルが開きます。
-
[Save] (保存)をクリックして設定を保存します。
レコードがフィルタリングされ、定義した基準を満たしているレコードは6件であることがわかります。
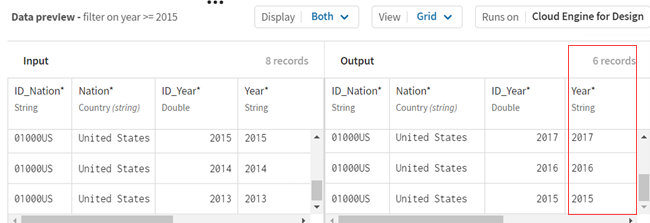
-
(オプション)この段階でパイプラインを実行すると、フィルタリングされたレコードが定義済みフィルターに従って渡されたことがログに表示され、Google BigQueryアカウントに作成された新しいNation_statisticsテーブルが表示されます。この新しいテーブルには、米国で収集された統計でフィルタリングされた6つのレコードが含まれています。
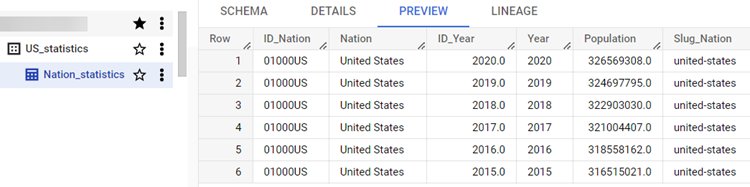
-
US data - statsソースの[Dataset] (データセット)テーブルに戻り、変数を追加して割り当てます。
![HTTPクライアントソースの[Configuration] (設定)パネルで、コンテキスト変数を追加できるXアイコンがNationという値の横で強調表示されます。](/ja-JP/pipeline-designer-user-guide/Cloud/Content/Resources/images/context_var-de_dataset.png)
-
[Query parameters] (クエリーパラメーター)で、drilldownsの[Value] (値)パラメーターの横にある
![[Context variable] (コンテキスト変数)](/ja-JP/pipeline-designer-user-guide/Cloud/Content/Resources/images/icon-var.png) アイコンをクリックし、[Add variable] (変数を追加)ウィンドウを開きます。
アイコンをクリックし、[Add variable] (変数を追加)ウィンドウを開きます。
-
[Query parameters] (クエリーパラメーター)で、drilldownsの[Value] (値)パラメーターの横にある
-
次にNation stats tableデスティネーションの[Dataset] (データセット)タブに移動し、変数を追加して割り当てます。
![BigQueryデスティネーションの[Configuration] (設定)パネルで、コンテキスト変数を追加できるXアイコンがNation_statisticsという値の横で強調表示されます。](/ja-JP/pipeline-designer-user-guide/Cloud/Content/Resources/images/context_var-output_dataset.png)
-
[Table name] (テーブル名)パラメーターの横にあるアイコンをクリックし、[Add a variable] (変数を追加)ウィンドウを開きます。
-
これで変数が作成されます。リダイレクト先の[Assign a variable]ウィンドウに全コンテキスト変数がリスト表示されます。ユーザーを選択して[Assign] (割り当て)をクリックします。
変数とその値は、BigQueryデータセットの[Table name] (テーブル名)パラメーターに割り当てられます。つまり、以前に定義したNationテーブル名がStateテーブルによって上書きされます。Nationテーブルにデータを挿入する代わりに、Stateテーブルにデータが挿入されます。
![[Assign a variable] (変数を割り当て)ウィンドウで、新しい変数が選択され、[Assign] (割り当て)ボタンが有効になります。](/ja-JP/pipeline-designer-user-guide/Cloud/Content/Resources/images/context_var_dataset-assign.png)
-
[Table name] (テーブル名)パラメーターの横にある
タスクの結果
パイプラインは実行中となり、データはフィルタリングされ、ソースデータセットとデスティネーションデータセットに割り当てたコンテキスト変数に対応します。
- パイプライン実行ログには、実行時に米国のデータを取得してBigQueryにStateテーブルを作成するために使用したコンテキスト変数が表示されます。312件のレコードが新しいテーブルに挿入されます。
![[Logs] (ログ)パネルには、312レコードが生成されたこと、およびBigQueryでUS Stateのデータを取得しStateテーブルを作成するために使われたコンテキスト変数がランタイムで適用されたことが示されています。](/ja-JP/pipeline-designer-user-guide/Cloud/Content/Resources/images/context_var_dataset-logs.png)
- Google BigQueryアカウントには、新しく作成され、フィルタリング済みのデータ(2015年以降に収集された米国のデータのみ)が入力されたState_statisticsテーブルが表示されます。
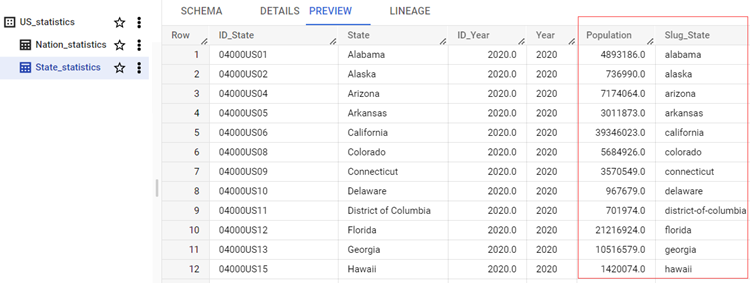
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。