
特定のKafkaトピックからメッセージを読み取る
手順
-
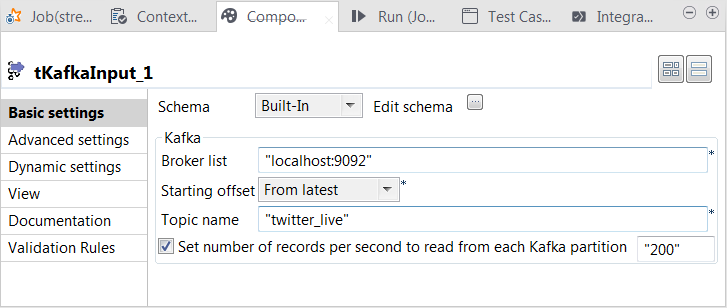
tKafkaInputをダブルクリックして、その[Component] (コンポーネント)ビューを開きます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。