
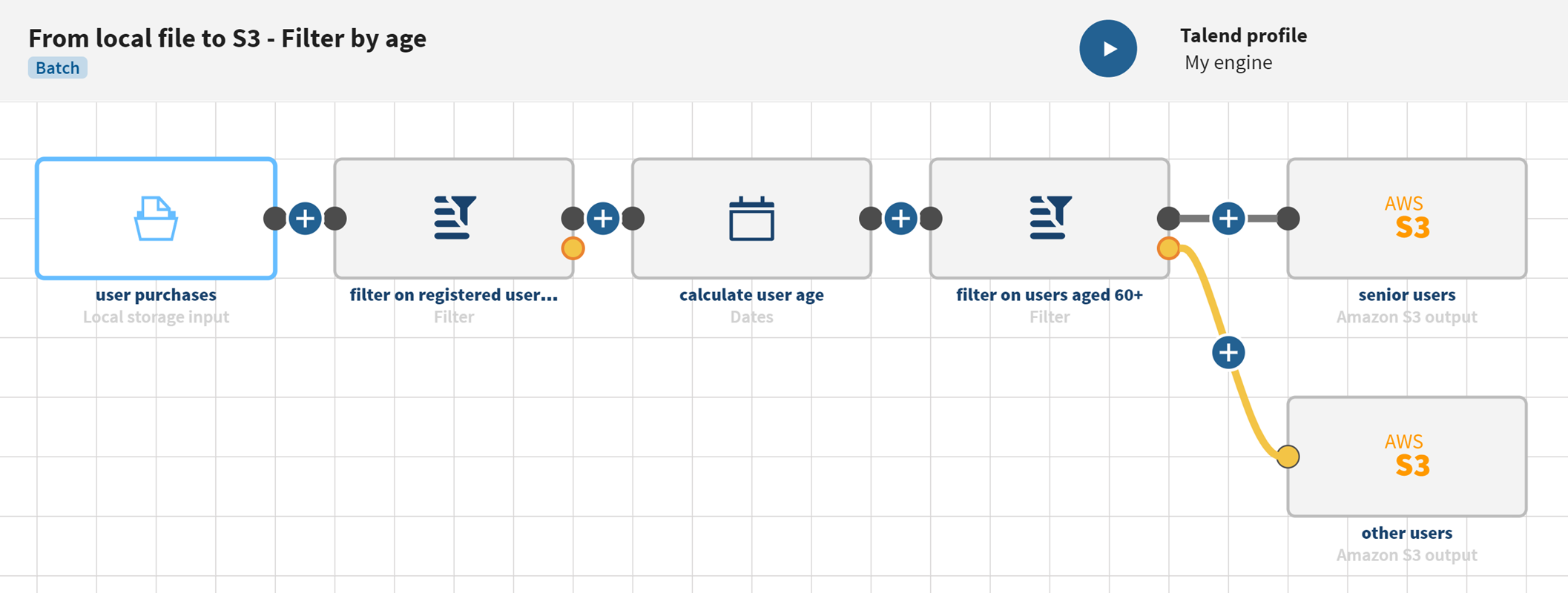
Filtern der Daten in einer lokalen Datei und Aufteilen der Daten auf zwei Amazon S3-Ausgaben
Dieses Szenario soll Sie bei der Einrichtung und Verwendung von Konnektoren in einer Pipeline unterstützen. Es wird empfohlen, dass Sie das Szenario an Ihre Umgebung und Ihren Anwendungsfall anpassen.
Vorbereitungen
- Wenn Sie dieses Szenario reproduzieren möchten, laden Sie folgende Datei herunter und extrahieren Sie sie: local_file-to_s3.zip. Die Datei enthält Daten zu Benutzerkäufen mit Angaben zu Registrierung, Kaufpreis, Geburtsdatum usw.
Prozedur
-
Klicken Sie auf das Symbol
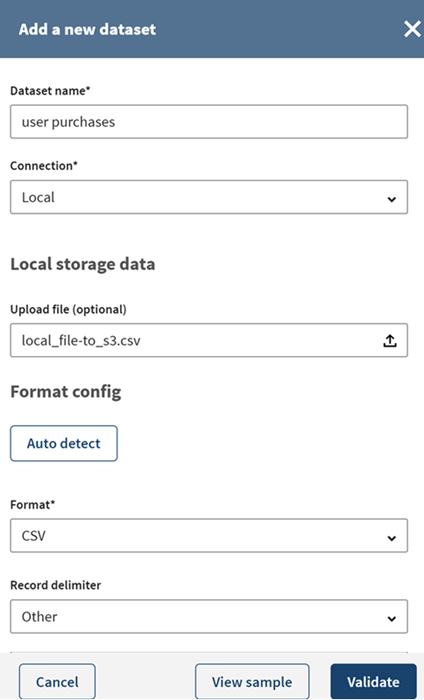
 , um die Datei local_file-to_s3.csv auf Ihrem Gerät zu suchen und auszuwählen, klicken Sie auf Auto detect (Autom. erkennen), damit die Informationen zum Dateiformat automatisch angegeben werden, und anschließend auf View sample (Sample anzeigen), um eine Vorschau Ihres Datensatz-Samples anzuzeigen.
, um die Datei local_file-to_s3.csv auf Ihrem Gerät zu suchen und auszuwählen, klicken Sie auf Auto detect (Autom. erkennen), damit die Informationen zum Dateiformat automatisch angegeben werden, und anschließend auf View sample (Sample anzeigen), um eine Vorschau Ihres Datensatz-Samples anzuzeigen.
-
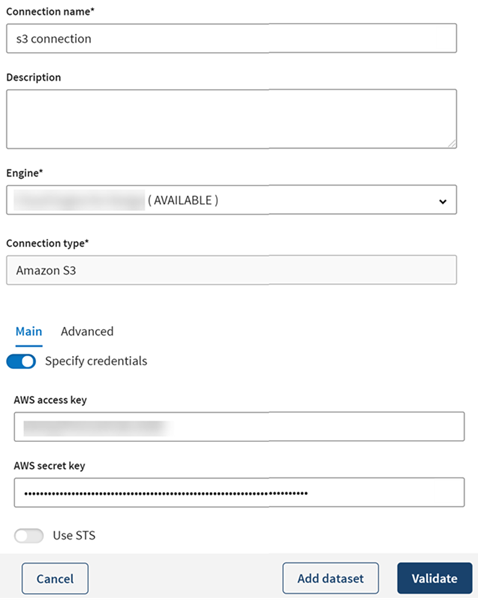
Gehen Sie genauso vor, um die Amazon S3-Verbindung und S3-Ausgaben hinzuzufügen, die als Ziele in Ihrer Pipeline fungieren sollen. Geben Sie die Verbindungseigenschaften gemäß der Beschreibung in Eigenschaften von Amazon S3 ein.
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Filter zur Pipeline hinzu, um die Benutzerdaten zu filtern, und geben Sie einen aussagekräftigen Namen für sie ein. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Filter zur Pipeline hinzu, um die Benutzerdaten zu filtern, und geben Sie einen aussagekräftigen Namen für sie ein. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Date (Datum) zur Pipeline hinzu, um das Alter der Benutzer auf der Grundlage ihres Geburtsdatums zu berechnen. Daraufhin wird das Konfigurationsfenster geöffnet.
-
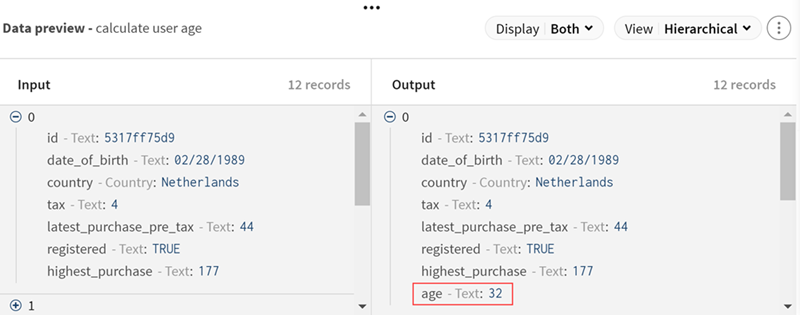
(Optional) Sehen Sie sich die Vorschau des Prozessors an, um das jeweils berechnete Alter zu prüfen.
-
Klicken Sie auf und fügen Sie einen weiteren Filter-Prozessor zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf
 für den FILTER-Prozessor, um ein anderes Ziel hinzuzufügen und um das Fenster zur Auswahl des zweiten Datensatzes zu öffnen, der die Ausgabedaten aufnehmen soll, die nicht Ihrem Filter entsprechen (S3).
für den FILTER-Prozessor, um ein anderes Ziel hinzuzufügen und um das Fenster zur Auswahl des zweiten Datensatzes zu öffnen, der die Ausgabedaten aufnehmen soll, die nicht Ihrem Filter entsprechen (S3).
-
(Option) Sehen Sie sich den Filter-Prozessor an, um eine Vorschau Ihrer Daten nach dem Filtervorgang zu erhalten: Alle registrierten Benutzer im Alter ab 60 Jahren.
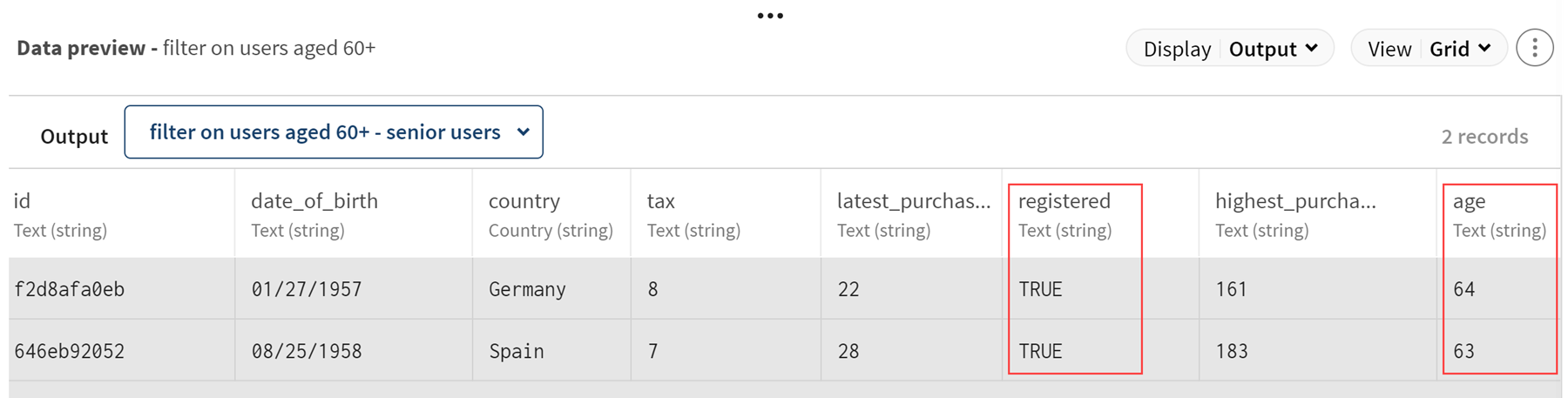
Ergebnisse
Ihre Pipeline wird ausgeführt, die in Ihrer lokalen Datei gespeicherten Benutzerinformationen wurden gefiltert, das Alter der Benutzer wurde berechnet und die Ausgabe-Flows werden an das von Ihnen definierte S3-Bucket gesendet. Die verschiedenen Ausgaben können jetzt beispielsweise für separate zielgerichtete Marketingkampagnen verwendet werden.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!